AI领域的竞争正愈演愈烈,马斯克旗下的xAI公司最新发布的Grok-3模型再次将这场“军备竞赛”推向高潮。Grok-3不仅在训练算力消耗上达到DeepSeek-V3的263倍,还在多项基准测试中刷新了SOTA(当前最优水平),超越了包括GPT-4o、Gemini-2 Pro和DeepSeek-V3在内的其他主流AI模型。


算力消耗:Grok-3的“壕气”与DeepSeek的“巧思”
Grok-3的诞生离不开庞大的算力支持。xAI团队在短短122天内搭建了第一批10万块GPU的集群,并在92天内将其扩展到20万块,成为目前全球最大的完全连接的H100集群。相比之下,DeepSeek-V3模型仅使用了2048块英伟达H800 GPU进行训练。Grok-3的训练算力消耗是DeepSeek-V3的263倍,这种“大力出奇迹”的策略让Grok-3在短时间内实现了性能的飞跃。
然而,DeepSeek却选择了另一条技术路径。通过分布式算力+混合云优化的方式,结合自研的模型压缩技术,DeepSeek在千亿参数规模下实现了训练成本降低40%以上。这种“巧思”不仅节省了资源,还为AI行业提供了一种新的发展思路。

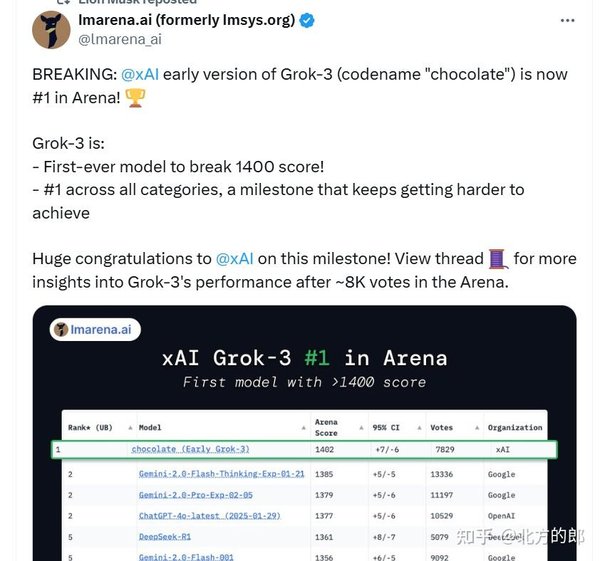
基准测试:Grok-3的全面领先
在官方公布的基准测试中,Grok-3在数学、科学和编程等多个领域表现优异,超越了GPT-4o、Gemini-2 Pro和DeepSeek-V3等竞争对手。例如,在AIME(数学问题评估)和GPQA(博士级别物理、生物和化学问题评估)测试中,Grok-3均取得了领先成绩。
然而,用户的实际体验却并非完全一致。尽管Grok-3在响应速度上远超其他模型,但在逻辑推理和中文理解能力上,它并未与DeepSeek-R1拉开显著差距。例如,在面对“弱智吧”的复杂逻辑问题时,Grok-3的表现甚至不如DeepSeek-R1。

开源与闭源:不同的商业模式
Grok-3的发布也引发了关于开源与闭源的讨论。马斯克宣布,Grok-3将在未来开源其上一个版本(Grok-2),而当前版本则采用“基础版开源+高级功能付费”的策略。这种模式既能吸引开发者贡献算力,又能通过开源生态倒逼竞争对手。
相比之下,DeepSeek选择了全面开源的策略。其开源大模型的出圈不仅吸引了包括微软、英伟达、亚马逊等世界级巨头的合作,还推动了新质生产力的发展。Gartner高级分析师Mike Fang认为,DeepSeek的开源模式虽然短期内不以盈利为目的,但其对行业的影响力和推动力不可忽视。
资本市场的反应
这场AI军备竞赛不仅推动了技术进步,也引发了资本市场的强烈反应。Grok-3的发布后,相关股票价格出现波动,投资者对AI行业的未来充满期待。然而,Grok-3的实际表现是否能够支撑其高昂的估值,仍需市场进一步验证。
结语
Grok-3的发布标志着AI军备竞赛进入了一个新的阶段。无论是“大力出奇迹”的算力堆砌,还是“巧思”创新的技术路径,AI行业的发展正在加速。未来,谁能在技术、商业模式和实际应用中取得平衡,谁将在这场竞赛中脱颖而出。我们正站在时代的潮头,需要以开放的心态拥抱这场变革。




