Muon优化器的技术突破
月之暗面团队在预训练模型领域取得了重要进展,其核心在于对Muon优化器的改进。Muon是一种神经网络隐藏层的2D参数优化器,最初由OpenAI提出,主要用于小型模型和数据集。然而,月之暗面团队通过一系列创新,成功将Muon应用于大规模预训练模型,显著降低了算力需求。

改进Muon的关键技术
-
引入权重衰减机制:在权重更新公式中添加衰减系数,防止模型权重和层输出幅度超出高精度表示范围,从而提升模型性能。
-
调整参数更新尺度:使不同形状矩阵参数的更新幅度保持一致,并与AdamW的更新幅度匹配,简化超参数设置。
-
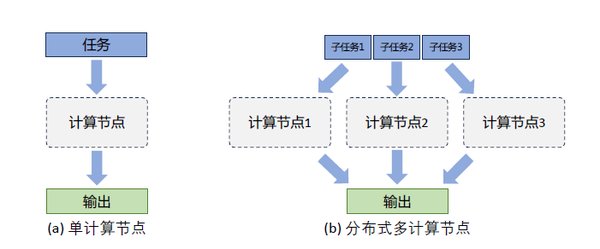
分布式训练扩展:通过梯度聚合通信和并行计算正交化更新量,将Muon扩展到分布式训练环境中,最小化内存占用和通信开销。
实验验证与成果
在Llama架构的一系列稠密模型上,月之暗面团队进行了Muon和AdamW的模型缩放对比实验。结果显示,Muon的样本效率是AdamW的1.92倍,训练FLOPS仅为AdamW的52%,达到了相当的性能。这一发现证实了Muon在大规模训练中的效率优势。
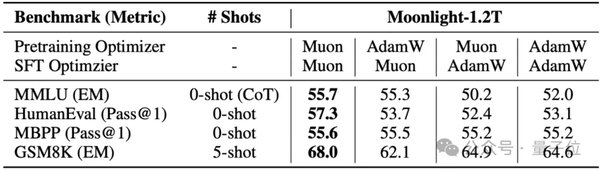
Moonlight模型的卓越表现
基于改进后的Muon优化器,月之暗面团队训练了Moonlight模型,这是一个具有15.29B总参数和2.24B激活参数的MoE模型。Moonlight在各类任务上均取得了显著优于同类模型的性能,包括英语理解与推理、代码生成、数学推理和中文理解等。即使与使用更大数据集训练的稠密模型相比,Moonlight也展现了极强的竞争力。
帕累托前沿的推进
Moonlight模型在性能-训练预算平面上推进了帕累托前沿,即在多个目标之间实现了最佳平衡。这一成果不仅展示了Muon优化器的强大潜力,也为未来多模态和长文本推理能力的发展提供了有力支持。
未来发展方向
月之暗面内部已将“持续拿到SOTA结果”确定为最重要的工作目标,并计划在2025年加强多模态和长文本推理能力。由于DeepSeek的成功,外界重新审视了月之暗面的技术和用户增长模式。有业内人士透露,月之暗面可能会将强化学习作为一个工作重点方向,以对抗DeepSeek等竞争对手。
强化学习的潜在应用
强化学习作为一种有效的训练方法,有望在预训练模型领域发挥重要作用。通过引入强化学习,月之暗面可以进一步提升模型的泛化能力和适应性,从而在激烈的市场竞争中占据优势。
结语
月之暗面团队通过改进Muon优化器,成功将其应用于大规模预训练模型,显著降低了算力需求并提升了模型性能。这一技术突破不仅验证了Muon在大规模训练中的可行性,还为未来多模态和长文本推理能力的发展奠定了基础。随着强化学习等新技术的引入,月之暗面有望在预训练模型领域取得更多突破,推动行业向前发展。