FlashMLA:AI推理效率的革命性突破
DeepSeek最近开源的FlashMLA项目在AI领域引起了广泛关注。作为一种针对Hopper GPU优化的高效MLA(Multi-Head Latent Attention)解码内核,FlashMLA不仅显著提升了AI推理效率,还大幅降低了成本。这一技术突破为AI行业带来了新的可能性。
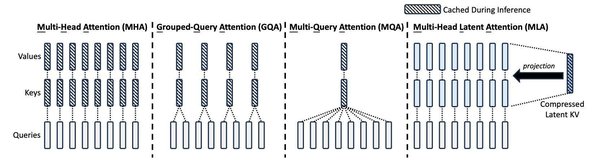
技术原理:多头潜在注意力机制
FlashMLA的核心是多头潜在注意力(MLA)机制。传统的多头注意力(MHA)虽然能有效处理语言信息,但需要大量内存存储信息,导致资源浪费。MLA通过低秩分解技术,将大仓库压缩成小仓库,既节省了空间,又保持了高效性能。这种优化使得FlashMLA在处理长序列文本和实时应用(如聊天机器人和虚拟助手)时表现出色。
性能优势:高效计算与内存优化
FlashMLA在Hopper GPU上的表现尤为突出。在内存带宽受限的配置下,FlashMLA可达到3000 GB/s的带宽,而在计算能力受限的配置下,其计算效率高达580 TFLOPS。这意味着同样的GPU资源可以处理更多请求,从而降低单位推理成本。对于AI公司和云计算服务商来说,这无疑是一个巨大的优势。

应用场景:广泛且实用
FlashMLA的主要应用场景包括:
-
长序列处理:适合处理数千个标记的文本,如文档分析或长对话。
-
实时应用:如聊天机器人、虚拟助手和实时翻译系统,降低延迟。
-
资源效率:减少内存和计算需求,便于在边缘设备上部署。
开源意义:打破技术壁垒
FlashMLA的开源意味着更多小型AI公司和独立开发者也能用上这一高效技术。过去,这些高效AI推理优化技术通常掌握在OpenAI、英伟达等巨头手中。如今,随着FlashMLA的开源,更多人进入AI领域创业,有望催生更多的AI创业项目。
中美AI技术竞争
在中美AI技术竞争中,中国在计算能力和工业能力上展现出显著优势。美国通过出口管制限制中国AI发展的策略,并未能阻止中国在AI领域的快速进步。FlashMLA的开源,不仅是中国AI技术自主创新的体现,也是对全球AI生态的重要贡献。
结语
DeepSeek的FlashMLA项目通过技术创新和开源策略,为AI推理效率带来了革命性突破。这一技术不仅提升了AI应用性能,还降低了成本,为更多AI创业项目提供了可能。随着中美在AI技术领域的竞争加剧,FlashMLA的开源无疑为全球AI生态注入了新的活力。




