在人工智能领域,大型语言模型(LLM)的竞争日益激烈。近日,韩国人工智能基础设施解决方案公司MOREH宣布在Hugging Face上发布其自主开发的韩语大型语言模型“Llama-3-Motif-102B”,并开源。这一模型的发布标志着韩语AI技术的一个重要里程碑。
模型概述
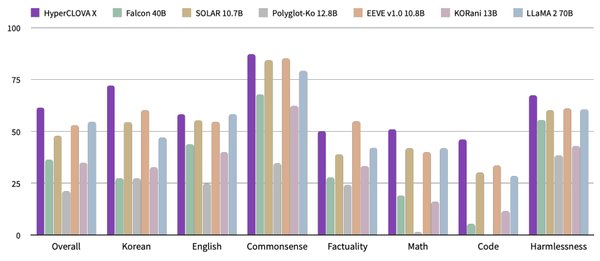
Llama-3-Motif-102B拥有1020亿个参数,是目前韩语AI模型中规模最大的之一。该模型在韩语AI性能评估系统KMMLU基准测试中得分高于OpenAI的GPT-4,展现了其在韩语理解和生成方面的卓越能力。


技术优势
MOREH负责人表示,Llama-3-Motif-102B的出色表现得益于以下几个关键因素:
-
大量的韩语学习数据:模型使用了包括专业领域文档在内的广泛训练数据,确保了其在各种语境下的表现。
-
独特的学习技术:MOREH开发了专门针对韩语的学习算法,使得模型能够更好地理解和生成韩语文本。
开源与社区贡献
Llama-3-Motif-102B的开源发布不仅为研究人员和开发者提供了强大的工具,也促进了韩语AI技术的普及和发展。通过Hugging Face平台,用户可以轻松访问和使用这一模型,进行各种自然语言处理任务。
未来展望
随着Llama-3-Motif-102B的发布,韩语AI技术迈上了一个新的台阶。未来,MOREH计划继续优化模型性能,并探索更多应用场景,如智能客服、自动翻译和内容生成等。这一模型的成功也为其他语言的大型语言模型开发提供了宝贵的经验和参考。
Llama-3-Motif-102B的发布不仅是韩语AI技术的一大进步,也为全球AI社区带来了新的机遇和挑战。我们期待看到更多基于这一模型的创新应用和研究成果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。