在人工智能技术快速发展的今天,如何以更低的成本实现更高的性能,成为全球AI企业共同面临的挑战。中国人工智能初创企业深度求索(DeepSeek)通过创新的多头潜在注意力机制(MLA)等技术,成功打破了这一瓶颈,为AI行业带来了全新的解决方案。
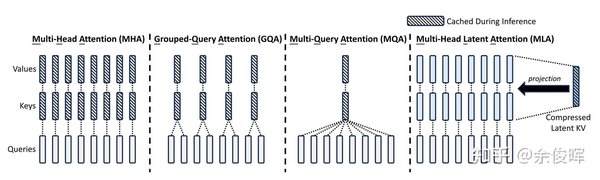
什么是多头潜在注意力机制?
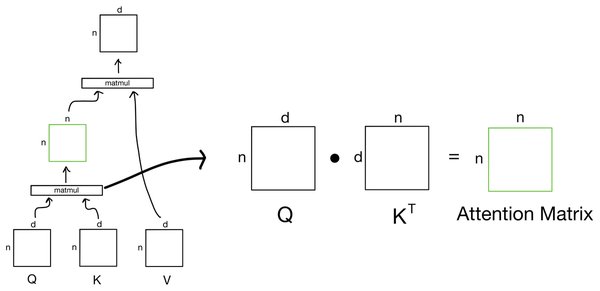
多头潜在注意力机制(MLA)是深度求索在传统多头注意力机制(MHA)基础上的重大创新。传统的MHA在处理长序列数据时,显存占用大、计算复杂度高,而MLA通过引入潜在化概念,对输入信息进行预处理和选择性压缩,显著减少了参数数量。这一创新不仅降低了显存占用至传统方法的5%-13%,还大幅提升了推理效率,使模型在资源受限的环境下仍能保持高性能。
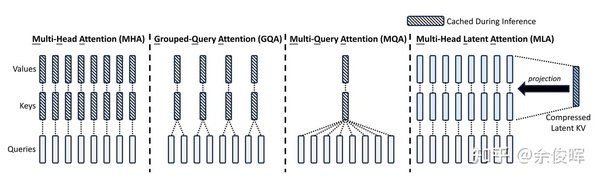
MLA的技术优势与应用场景
深度求索的MLA技术在多个领域展现了其独特优势:
-
长上下文处理能力:MLA通过优化注意力机制,增强了对长序列数据的理解能力,特别适用于文本生成、对话系统等任务。
-
低成本推理:MLA显著降低了推理过程中的资源消耗,使模型在低算力设备上也能高效运行。
-
开源生态支持:深度求索将MLA技术开源,吸引了全球开发者参与优化,进一步推动了技术的普及与应用。

FlashMLA与DeepEP:芯片性能优化的开源利器
深度求索近期开源的两个项目——FlashMLA和DeepEP,进一步展示了其在芯片性能优化方面的实力:
-
FlashMLA:专为英伟达Hopper GPU优化的高效MLA解码内核,针对可变长度序列进行了深度优化,显著提升了处理效率。
-
DeepEP:首个用于混合专家架构(MoE)模型训练和推理的开源EP通信库,支持高效的全员沟通、NVLink和RDMA,实现了计算与通信的重叠,进一步降低了训练成本。
低成本训练背后的创新
深度求索的成功不仅在于技术突破,更在于其创新的商业模式和开源策略。通过混合专家架构(MoE)和MLA技术的结合,深度求索在训练成本上实现了显著优化。例如,其DeepSeek-V3模型仅用2048张英伟达H800 AI芯片,以557.6万美元的低成本完成了训练,远低于行业平均水平。
开源社区的反响与未来展望
深度求索的开源项目赢得了全球开发者的一致好评。美国旧金山AI行业解决方案提供商龙鳞工业公司的首席技术官斯蒂芬·皮门特尔表示,深度求索的开源举措“有力驳斥了外界对其虚报成本的指控”。开源社区的积极参与,也为深度求索的技术迭代和生态建设注入了新的活力。
未来,深度求索将继续探索光子计算、存算一体等新型架构,进一步降低对高算力芯片的依赖,推动AI技术的普及与应用。正如深度求索创始人梁文锋所言:“AI不应被巨头垄断,而应普惠众生。”
结语
深度求索通过多头潜在注意力机制等创新技术,不仅展示了中国AI企业的技术实力,也为全球AI行业提供了低成本、高性能的解决方案。其开源策略和技术突破,正在引领AI技术生态的变革,为全球开发者与企业带来更多可能性。在AI竞赛的马拉松中,深度求索以其独特的“进化韧性”,正在书写中国AI技术的新篇章。






