在人工智能领域,训练大型语言模型(LLM)通常需要大量的计算资源和时间。然而,GitHub上热门的AI项目MiniMind,通过采用直接偏好强化学习(DPO)算法等先进技术,成功实现了从零开始训练超小语言模型的目标,仅需3块钱成本和2小时时间。
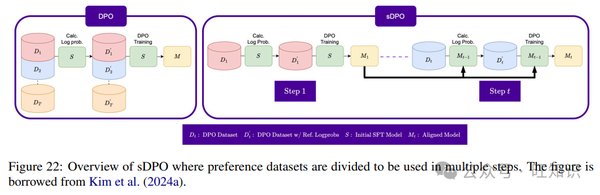

DPO算法的核心优势
MiniMind项目中的DPO算法是其成功的关键之一。DPO算法通过直接优化模型的偏好,使得模型在训练过程中能够更好地适应特定任务。这种算法不仅提高了训练效率,还显著降低了计算资源的消耗。
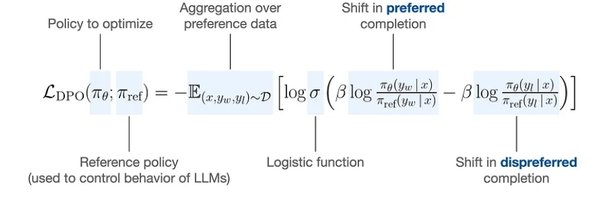

极简结构与开源代码
MiniMind项目开源了大模型的极简结构,包括数据集清洗、预训练、监督微调、LoRA微调、DPO算法和模型蒸馏等全过程代码。所有核心算法代码均从零使用PyTorch原生重构,不依赖第三方库提供的抽象接口,为开发者提供了极大的灵活性和可定制性。

低成本与高效率的训练
MiniMind项目展示了如何在极低的成本和短时间内训练出高效的超小语言模型。通过优化训练流程和采用先进的算法,MiniMind能够在NVIDIA 3090上仅用2小时完成训练,成本低至3块钱。这种高效率的训练方法为资源有限的开发者提供了新的可能性。
多模态拓展:MiniMind-V
除了语言模型,MiniMind项目还拓展了视觉多模态的MiniMind-V。这种多模态模型能够处理图像和文本等多种数据类型,进一步提升了模型的应用范围和实用性。
总结
MiniMind项目通过DPO算法和极简结构,成功实现了低成本、高效率的超小语言模型训练。该项目不仅为AI社区提供了低门槛的学习和实践机会,还展示了未来AI发展的新方向。通过开源代码和多模态拓展,MiniMind为开发者提供了丰富的工具和资源,推动了AI技术的普及和创新。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...







AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。