在人工智能领域,大模型的开发一直是各大科技公司的焦点。从OpenAI的GPT系列到Google的BERT和T5,再到DeepMind的Gopher和Chinchilla,这些模型在文本生成、理解、对话系统等领域表现出色,推动了人工智能技术的进步。然而,随着模型规模的不断扩大,效率和性能的优化成为了新的挑战。DeepMind的Chinchilla模型正是在这一背景下应运而生,通过优化模型大小和训练数据量的平衡,实现了性能的显著提升。
传统大模型的局限
自2020年OpenAI提出“规模定律”以来,各大公司纷纷通过增加模型参数来提升性能。然而,这种“越大越好”的策略逐渐显露出其局限性。尽管GPT-3、LaMDA、Jurassic-1等模型在性能上超越了前代,但它们并未达到理论上的最优状态。DeepMind的最新研究表明,单纯增加模型大小并不是提升性能的最佳途径,训练数据量的优化同样至关重要。
Chinchilla的创新之处
Chinchilla模型的核心创新在于其“计算优化”策略。通过对模型大小和训练数据量的平衡优化,Chinchilla在相同的计算预算下,实现了比Gopher、GPT-3等模型更优的性能。具体来说,Chinchilla拥有70亿参数,是Gopher的四分之一,但训练数据量却是Gopher的四倍。这种策略使得Chinchilla在多个语言基准测试中均表现优异,甚至超越了专家预测的2023年SOTA水平。
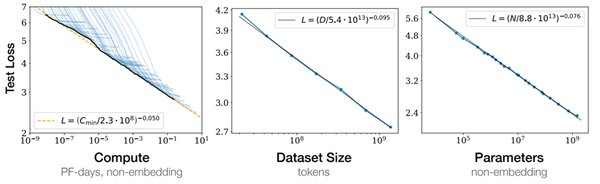
性能对比与优势
Chinchilla在多个关键基准测试中展现了其卓越的性能:
-
MMLU基准测试:Chinchilla的平均准确率达到了67.6%,比Gopher高出7.6%。
-
BIG-bench基准测试:Chinchilla的平均准确率为65.1%,比Gopher高出10.7%。
-
阅读理解测试:在LAMBADA数据集上,Chinchilla的准确率为77.4%,超越了Gopher和MT-NLG 530B。
-
封闭式问答测试:在Natural Questions和TriviaQA数据集上,Chinchilla均取得了新的SOTA成绩。
未来大模型的发展方向
Chinchilla的成功不仅在于其性能的提升,更在于其为未来大模型的发展提供了新的方向。通过优化模型大小和训练数据量的平衡,Chinchilla证明了“越小越好”的可能性。这一发现有望降低大模型的训练和推理成本,使得更多中小型公司和研究机构能够参与到人工智能的研究中来。
此外,Chinchilla的研究还揭示了当前大模型普遍存在的“训练不足”问题。未来,随着高质量数据集的增加,大模型的性能有望进一步提升。然而,这也带来了数据安全和伦理问题,如何在提升性能的同时确保模型的安全性和公平性,将是未来研究的重要课题。
结论
Chinchilla模型的出现标志着大模型技术进入了一个新的阶段。通过优化模型大小和训练数据量的平衡,Chinchilla不仅提升了性能,还为大模型的未来发展提供了新的思路。未来,随着更多创新技术的引入,大模型有望在更广泛的领域发挥其潜力,推动人工智能技术的进一步发展。
通过Chinchilla的成功,我们可以看到,人工智能的未来不仅在于模型的规模,更在于如何通过创新和优化,实现性能和效率的双重提升。









