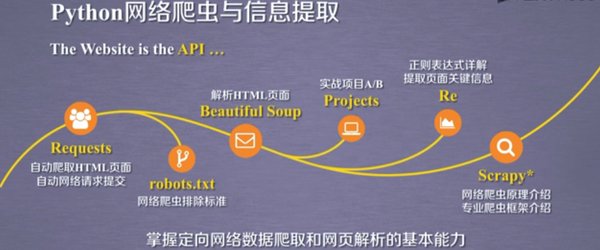

网络爬虫技术的基本原理
网络爬虫是一种自动化程序,通过模拟人类浏览器的行为,自动访问网页并提取数据。其核心原理包括发送HTTP请求、解析网页内容以及存储提取的数据。Python作为网络爬虫开发的常用语言,提供了丰富的库和工具,如requests、BeautifulSoup和Scrapy等,使得编写网络爬虫变得简单高效。

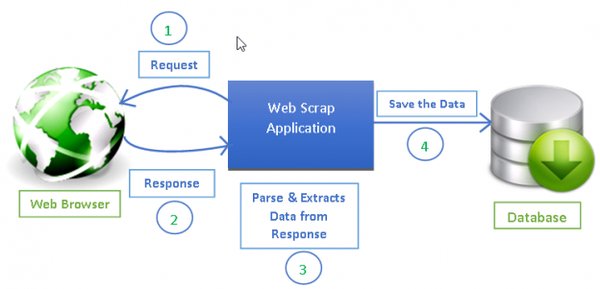
网络爬虫在品牌保护中的应用
在品牌保护中,网络爬虫技术可以用于监控网络上的乱价现象,帮助品牌方及时发现问题并采取行动。以下是网络爬虫在品牌保护中的主要应用场景:
-
价格监控:通过抓取电商平台上的商品价格数据,品牌方可以实时监控价格波动,识别乱价行为。
-
产品信息抓取:抓取产品描述、评论等信息,分析是否存在假冒伪劣产品或虚假宣传。
-
竞品分析:通过抓取竞争对手的产品信息和价格策略,为品牌制定更有效的市场策略提供数据支持。

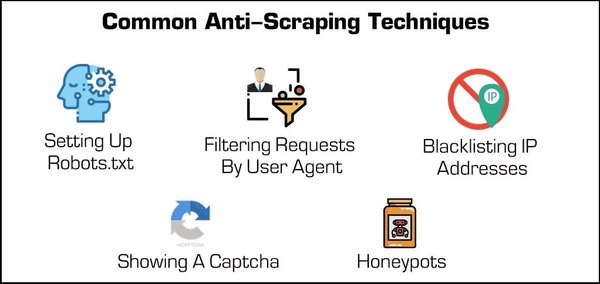
网络爬虫的常用技术
网络爬虫的技术不断发展,以下是几种常用的技术:
-
聚焦爬虫技术:聚焦爬虫是一种主题网络爬虫,通过链接评价和内容评价模块,确保抓取的信息与特定主题高度相关。
-
基于链接评价的爬行策略:通过分析网页中的链接结构,评估链接的重要性,从而优化爬取路径。
-
基于内容评价的爬行策略:利用文本相似度算法,如Fish-Search和Shark-Search,计算页面与主题的相关度,确保抓取内容的高相关性。
网络爬虫的注意事项与道德问题
在使用网络爬虫技术时,品牌方需要遵守以下注意事项和道德规范:
-
遵守网站的使用条款:确保爬虫行为符合目标网站的规定,避免触发反爬虫机制。
-
尊重隐私权和版权:不得未经授权获取敏感信息或侵犯他人的知识产权。
-
控制爬取频率:合理设置爬取频率,避免对目标网站造成过大的访问压力。
结语
网络爬虫技术为品牌保护提供了强大的数据支持,能够帮助品牌方高效监控网络乱价现象,维护品牌权益。然而,在使用这一技术时,品牌方需谨慎行事,遵守相关法律和道德规范,确保技术应用的合法性与合理性。通过合理利用网络爬虫技术,品牌方可以在激烈的市场竞争中占据更有利的地位。




