2024年5月13日,OpenAI发布了其最新、最先进的AI模型——GPT-4o。这一模型的推出不仅标志着人工智能领域的一次重大飞跃,更预示着多模态AI交互的新时代正式到来。GPT-4o以其卓越的性能、更快的响应速度和更低的成本,正在重新定义人机交互的可能性。


什么是GPT-4o?
GPT-4o中的“o”代表“omni”,意为“全面”或“通用”。这款模型基于GPT-4 Turbo构建,但在架构和功能上进行了革命性创新。与之前的模型不同,GPT-4o采用了单一神经网络处理所有输入数据,包括文本、语音、图像甚至视频。这种设计使其能够无缝融合多模态信息,从而生成更丰富、更符合上下文的输出内容。
例如,GPT-4o不仅能够解析语音输入中的背景噪音和情感色彩,还能在生成多语种输出时保持高质量。无论是英语还是其他语言,用户都能享受到GPT-4o卓越的自然语言生成能力。
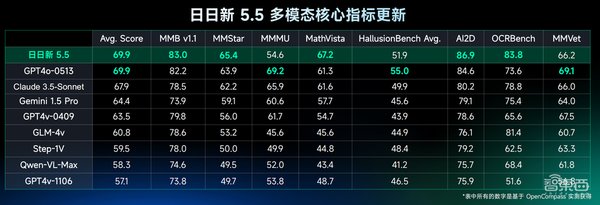

GPT-4o的性能优势
GPT-4o在多个方面展现了显著的性能提升,尤其是在推理速度、吞吐量和多模态处理能力上:
-
更快的响应速度:GPT-4o的推理速度是GPT-4 Turbo的两倍,平均响应时间仅为320毫秒,接近人类对话的反应时间。
-
更高的吞吐量:GPT-4o每秒可生成109个令牌,远超GPT-4 Turbo的20个令牌,为实时应用提供了更高的效率。
-
更低的使用成本:GPT-4o的API费用仅为GPT-4 Turbo的一半,使其成为开发者更具性价比的选择。

多模态能力的革命性突破
GPT-4o的最大亮点在于其多模态融合能力。它能够同时处理文本、语音、图像和视频输入,并生成相应的输出。这种能力使其在多个应用场景中展现出巨大潜力:
-
智能语音助手:GPT-4o可以实时理解语音指令,并观察周围环境,提供更自然的交互体验。
-
视觉处理:改进的视觉处理能力使其能够更准确地解释和响应图像内容。
-
跨语言沟通:GPT-4o能够实时翻译多种语言,打破语言障碍,促进全球协作。
应用场景与未来展望
GPT-4o的多模态能力为人工智能应用开辟了新的可能性。以下是其潜在的应用场景:
-
实时视频分析:结合计算机视觉技术,GPT-4o可用于智能监控、内容审核等领域。
-
多模态虚拟助手:与语音识别框架集成,打造更智能的虚拟助手,提供个性化服务。
-
高保真图文生成:基于文本和图像的双模态生成能力,GPT-4o可应用于广告设计、内容创作等领域。
此外,OpenAI还在探索GPT-4o在音乐创作、面试模拟和语言学习等方面的应用。例如,两个GPT-4o模型可以互动甚至一起唱歌,为AI驱动的音乐创作开辟新形式。
安全性与责任
OpenAI在开发GPT-4o时,始终将安全性放在首位。通过多模态安全设计、严格的风险评估和外部红队测试,OpenAI确保GPT-4o在所有功能中都具备安全性和可靠性。例如,音频功能将分阶段推出,并受现有安全协议的约束,以降低潜在风险。
结语
GPT-4o的推出不仅是技术上的突破,更是人机交互方式的革新。其多模态能力、更快的响应速度和更低的成本,将加速人工智能在各行各业的普及。随着OpenAI不断探索GPT-4o的潜力,我们有理由相信,未来的AI交互将更加自然、智能和高效。
无论是开发者还是普通用户,GPT-4o都将成为解锁AI潜力的关键工具。准备好迎接这场人工智能革命了吗?







