
多模态技术的定义与发展
多模态技术是指能够同时处理和理解多种数据模态(如文本、图像、音频、视频等)的人工智能技术。近年来,随着深度学习技术的进步,多模态模型逐渐成为AI领域的研究热点。从早期的单模态模型到如今的多模态融合,AI技术在视觉与语言的结合上取得了显著进展。

Kosmos-1与GPT-4:多模态模型的代表
Kosmos-1是微软推出的一款多模态模型,能够分析图像内容、解决视觉难题并理解自然语言指令。它的出现标志着多模态技术在视觉与语言结合上的突破。而GPT-4作为OpenAI的最新成果,不仅延续了GPT系列在自然语言处理上的优势,还引入了图像模态,使其能够处理更加复杂的多模态任务。
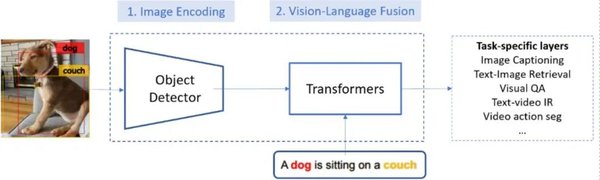

视觉语言模型的创新:Flamingo与BLIP-2
Flamingo是DeepMind提出的一种视觉语言模型,通过感知重采样模块和门控注意力机制,实现了视觉与语言的无缝结合。Flamingo的架构创新包括桥接预训练视觉模型和语言模型、处理任意交错排列的视觉和文本数据序列,以及无缝接收图像或视频作为输入。BLIP-2则通过QFormer模块实现了类似的功能,两者在多模态任务中都展现出了强大的少样本学习能力。
多模态技术的应用与挑战
多模态技术在实际应用中展现出广阔的前景,例如在视觉问答、图像描述、视频分析等领域。然而,多模态模型也面临着数据融合、计算复杂度高、模型训练难度大等挑战。未来,如何进一步提升多模态模型的效率和泛化能力,将是研究人员需要解决的关键问题。
未来展望:语音与视频的融合
随着技术的进步,语音和视频的融合将成为多模态技术的下一个重要方向。微软在Build 2024大会上推出的Copilot+ PC,展示了多模态技术在本地化应用中的潜力。从图像到语音,再到视频,多模态技术将不断拓展其应用边界,为AI技术的发展注入新的活力。
多模态技术的崛起,标志着AI技术在视觉与语言结合上的重大突破。从Kosmos-1到GPT-4,多模态模型不断刷新着我们对AI能力的认知。未来,随着技术的进一步成熟,多模态技术将在更多领域发挥其独特优势,推动AI技术的全面发展。











