SmolVLM-256M:轻量级视觉语言模型的突破
近日,Hugging Face 发布了两款多模态模型 SmolVLM-256M 和 SmolVLM-500M,其中 SmolVLM-256M 以其小巧的体积和高效的性能引起了广泛关注。作为世界上最小的视觉语言模型,SmolVLM-256M 在性能和资源需求之间实现了完美的平衡,为移动平台和边缘计算设备带来了新的可能性。
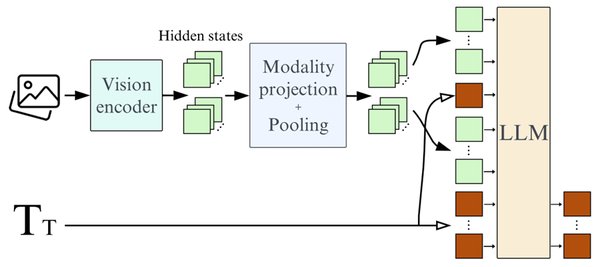
技术架构与核心组件
SmolVLM-256M 的技术架构基于 SigLIP 图片编码器和 SmolLM2 文本编码器。SigLIP 是一种高效的图片编码器,能够快速处理任意序列的图片输入;而 SmolLM2 则是一种轻量级的文本编码器,能够处理复杂的文本输入并生成高质量的文字输出。这种组合使得 SmolVLM-256M 能够接受任意序列的图片和文本输入,并生成相应的文字输出。
性能与资源需求
SmolVLM-256M 的最大亮点在于其轻量级的设计。该模型仅需不到 1GB 的 GPU 显存便可在单张图片上完成推理,这使得它非常适合在移动平台和边缘计算设备上运行。相比于传统的视觉语言模型,SmolVLM-256M 在保持高性能的同时,大幅降低了资源需求,为开发者提供了更多的灵活性。
应用场景
由于 SmolVLM-256M 的轻量级设计,它可以在多种场景下发挥重要作用。例如,在移动设备上,它可以用于实时图片识别和文字生成;在边缘计算设备上,它可以用于智能监控和自动化报告生成。此外,SmolVLM-256M 还可以与其他 AI 模型结合,构建更加复杂的多模态应用。
未来展望
随着技术的不断进步,视觉语言模型的应用场景将会越来越广泛。SmolVLM-256M 的出现,不仅为移动平台和边缘计算设备带来了新的可能性,也为多模态模型的发展指明了方向。未来,我们可以期待更多类似 SmolVLM-256M 的轻量级模型出现,进一步推动 AI 技术的普及和应用。
SmolVLM-256M 作为世界上最小的视觉语言模型,以其轻量级的设计和高效的性能,为多模态模型的发展开辟了新的道路。无论是在移动平台还是边缘计算设备上,SmolVLM-256M 都展现出了巨大的潜力,值得我们进一步关注和探索。





