大型语言模型(LLM)的竞争格局
近年来,大型语言模型(LLM)的竞争日益激烈,各大科技公司纷纷推出自己的模型,试图在这一领域占据领先地位。例如,马斯克旗下的人工智能初创公司xAI最近发布了新一代Grok 3大型语言模型,该模型在20万个英伟达H100 GPU上使用大量合成数据进行训练,参数规模估计超过2000亿个。这一发布引起了业界的广泛关注,也再次凸显了合成数据在LLM训练中的重要性。
合成数据的重要性
合成数据是指通过计算机生成的数据,而非从现实世界中采集的数据。在LLM的训练中,合成数据可以弥补真实数据的不足,提供更多的训练样本,从而提高模型的性能。多家公司在合成数据领域进行了技术积累和业务应用,例如汉仪股份、索辰科技、海天瑞声、浩瀚深度、拓尔思、星环科技、通鼎互联、科锐国际、虹软科技、利亚德和熵基科技等。这些公司通过合成数据技术,为LLM的训练提供了强大的支持。
模型蒸馏与提示工程
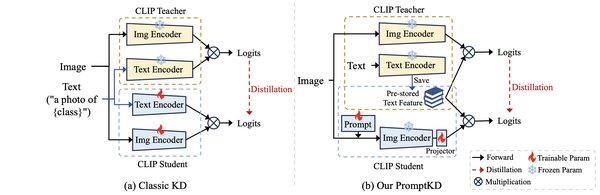
除了合成数据,模型蒸馏和提示工程也是LLM领域的关键技术。模型蒸馏是指将一个复杂的大模型(教师模型)的知识迁移到一个较小的模型(学生模型)中。这种方法可以在资源有限的情况下,尽可能地保持模型的性能。提示工程则是指通过设计特定的提示词或指令,引导LLM生成更符合预期的结果。提示工程不仅需要理解模型的底层逻辑,还需要对行业场景进行深入解构,设计出混合式工作流。
未来发展趋势
展望未来,LLM的竞争格局将继续演变。OpenAI在未来的领先优势可能会缩小,而谷歌、Meta等巨头通过垄断数据构建“护城河”的可能性增大。此外,随着预训练边际效益的递减,推理阶段的计算资源将占据更大的比例。卓越的基础设施和低成本推理技术将成为竞争的关键。
结论
大型语言模型(LLM)的竞争格局正在加速变化,合成数据、模型蒸馏和提示工程等关键技术将在未来的竞争中发挥重要作用。随着技术的不断进步,LLM的应用场景将更加广泛,其在工业生产、家庭服务等领域的潜力也将逐步释放。未来的LLM市场将充满机遇与挑战,只有那些能够快速适应变化、掌握核心技术的公司,才能在这一领域占据领先地位。
通过深入理解这些关键技术和发展趋势,我们可以更好地把握LLM的未来发展方向,为企业和个人在AI时代的竞争中赢得先机。