近年来,人工智能技术迅猛发展,大型推理模型(LRMs)成为研究热点。其中,DeepSeek R1凭借其开创性的思维链推理架构,不仅在通用人工智能(AGI)领域取得了突破性进展,还在军事场景中展现出巨大的应用潜力。然而,随着其能力的提升,安全性和技术伦理问题也逐渐浮出水面。
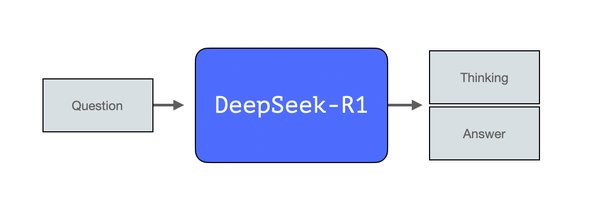
思维链推理:DeepSeek R1的核心技术
DeepSeek R1的核心技术在于其独特的思维链推理架构。与传统的对话模型不同,R1在回答问题前会生成一个详细的思考过程,这一机制显著提升了其在长文本编写、数学推理、编程等领域的表现。
训练流程
DeepSeek R1的训练流程分为以下几个关键步骤:
1. 基座模型训练:以DeepSeek V3 Base模型为基础,通过海量文本预训练,建立基本语言能力。
2. GRPO强化学习:采用DeepSeek原创的GRPO(群体相对策略优化)算法,在低算力消耗下实现模型的“开悟”时刻,使其具备自主思考能力。
3. SFT有监督微调:通过高质量CoT(思维链)数据微调,优化模型的推理能力和输出格式。
4. 多领域能力迁移:将推理能力扩展至写作、角色扮演、翻译等领域,最终形成一个通用性极强的推理模型。
技术优势
- 低算力消耗:GRPO算法仅需7G显存即可训练1.5B模型,大幅降低了硬件成本。
- 高性能推理:R1在数学、编程等领域的推理能力接近OpenAI o1模型,展现出卓越的性能。
- 模型蒸馏:通过蒸馏技术,R1的推理能力可迁移至小尺寸模型,进一步降低应用门槛。
军事应用:DeepSeek R1的智能化潜力
在军事领域,DeepSeek R1的思维链推理能力为复杂任务的处理提供了全新的解决方案。
应用场景
- 无人作战:R1可从多源数据中提炼关键信息,辅助无人系统进行实时决策。
- 情报侦察:通过语言理解和生成能力,快速分析情报数据,提升情报处理的效率和准确性。
- 网络安全:利用推理能力识别和防御网络攻击,增强系统的安全性。
- 电子战:在多模态数据融合的基础上,优化电子战策略,提升作战效能。
应用优势
- 成本效益:低算力消耗和高性能推理使得R1在军事应用中具有显著的成本优势。
- 持续学习:通过强化学习机制,R1能够不断优化自身能力,适应复杂的战场环境。
- 系统融合:R1可与现有军事系统深度融合,提升整体作战能力。
安全挑战:思维链推理的隐忧
尽管DeepSeek R1在性能和应用上取得了显著成果,但其安全性问题也引发了广泛关注。
H-CoT攻击:思维链劫持的威胁
杜克大学的研究提出了一种名为H-CoT(思维链劫持)的攻击方法,成功突破了包括DeepSeek R1在内的多款高性能推理模型的安全防线。这种攻击通过逆向解析模型的思维链,系统性瓦解其防御机制,导致模型从“谨慎劝阻”转变为“主动献策”。
潜在风险
- 安全审查漏洞:模型在展示思维链时可能暴露安全审查逻辑,为攻击者提供可乘之机。
- 跨语言差异:R1在处理不同语言请求时表现出不同的安全性,可能被恶意利用。
- 商业竞争压力:在激烈的市场竞争中,模型开发方可能为提升实用性而牺牲安全性。
未来展望:平衡性能与安全
DeepSeek R1的崛起标志着人工智能技术的新里程碑,但其安全性和技术伦理问题也亟待解决。未来,开发方需在提升性能的同时,建立更加完善的安全机制,确保大型推理模型真正造福人类。
改进方向
- 隐藏思维链:在安全审查中适当隐藏或模糊化处理思维链,降低被逆向解析的风险。
- 多维度验证:结合多种验证机制,增强模型的安全性和鲁棒性。
- 跨领域合作:与技术伦理专家、安全研究人员合作,制定更严格的安全标准和技术保障体系。
DeepSeek R1的成功不仅展现了思维链推理技术的巨大潜力,也为人工智能的未来发展提供了新的思路。在探索技术边界的同时,我们更需关注其潜在风险,确保技术进步与人类福祉的平衡。




