Transformer架构:AI革命的基石
Transformer架构自2017年提出以来,迅速成为人工智能领域的核心技术。其独特的自注意力机制和多层堆叠结构,使得模型在处理序列数据(如自然语言、图像等)时表现出色。如今,基于Transformer架构的大模型(如GPT系列、Claude系列等)已经在文本生成、代码编写、逻辑推理等任务中取得了突破性进展。
Transformer的核心技术
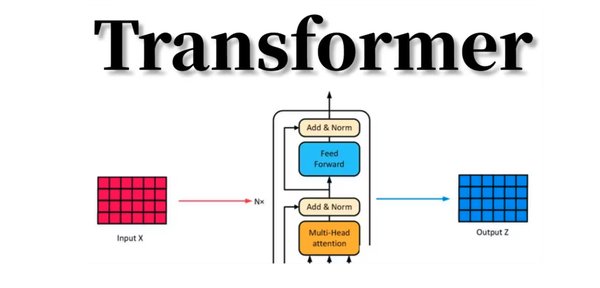
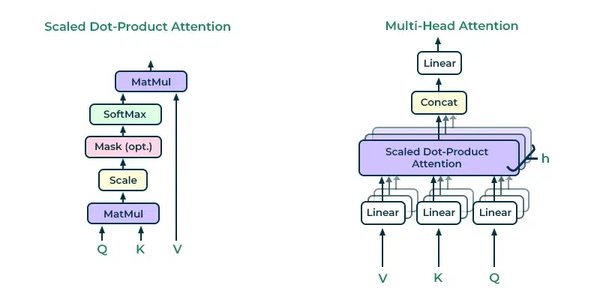
Transformer架构的核心在于其自注意力机制(Self-Attention),它能够捕捉输入序列中不同位置之间的依赖关系,从而更好地理解上下文信息。此外,Transformer的多层堆叠结构使得模型能够逐层提取更高层次的语义特征,进一步提升了模型的表达能力。
与传统的前馈神经网络相比,Transformer具有以下优势:
-
并行计算:Transformer可以同时处理序列中的所有位置,显著提高了计算效率。
-
长距离依赖:自注意力机制能够有效捕捉序列中远距离的依赖关系,解决了传统RNN和LRNN在处理长序列时的瓶颈问题。
-
可扩展性:通过增加模型层数和参数规模,Transformer的性能可以进一步提升,为大规模预训练模型(如GPT-3、BERT等)奠定了基础。
Transformer在大模型中的应用
基于Transformer架构的大模型已经在多个领域展现了强大的能力:
-
自然语言处理:GPT系列模型在文本生成、对话系统、翻译等任务中表现优异。
-
计算机视觉:Vision Transformer(ViT)将Transformer应用于图像分类任务,取得了与卷积神经网络(CNN)相媲美的效果。
-
多模态学习:多模态大模型(如CLIP、DALL-E)将Transformer与视觉、语言等信息结合,实现了跨模态的理解与生成。
Transformer的未来展望
尽管Transformer架构已经取得了巨大成功,但其发展仍面临诸多挑战与机遇:
1. 计算效率的提升
Transformer的推理复杂度较高,尤其是在处理长序列时,计算资源消耗巨大。如何优化模型的计算效率,降低推理成本,是未来研究的重要方向。例如,递归深度架构的提出,通过重复使用同一组参数,显著提升了模型的推理能力,为Transformer的优化提供了新思路。
2. 泛化能力的增强
大模型的泛化能力是其应用的关键。目前,基于Transformer的模型在特定任务上表现优异,但在开放、动态场景中的适应性仍有待提升。通过强化学习、自监督学习等方法,可以进一步增强模型的泛化能力,使其在复杂环境中表现出更强的适应性。
3. 多模态与具身智能的发展
多模态大模型和具身智能是Transformer架构的重要应用方向。多模态模型将语言、视觉、听觉等信息融合,实现了更全面的智能理解;具身智能则强调智能体与物理环境的交互能力,为通用人工智能(AGI)的实现提供了可能。
4. 开源与生态建设
开源是大模型发展的重要推动力。例如,DeepSeek的开源版本在文本生成、代码编写等任务中表现优异,为我国AI技术的发展注入了新的活力。未来,通过开源协作与生态建设,可以进一步推动Transformer技术的普及与应用。
结语
Transformer架构作为AI技术的基石,正在深刻改变我们的生活与工作方式。从自然语言处理到多模态学习,从大模型到具身智能,Transformer的潜力无限。然而,其发展也面临计算效率、泛化能力等多方面的挑战。未来,通过技术创新与生态建设,Transformer将继续引领AI革命,为智能时代的发展提供强大动力。





