Megatron:AI大模型训练的分布式解决方案
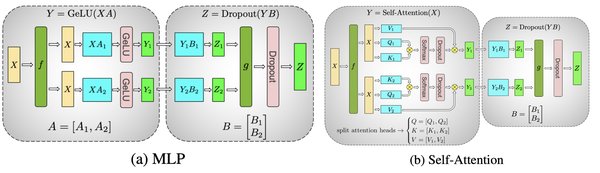
在AI大模型的训练过程中,算力需求巨大,尤其是像GPT-3这样的模型,其参数量高达1750亿,训练过程需要数千块GPU(如NVIDIA A100)和数万GPU小时。为了应对这一挑战,Megatron-LM作为一种分布式训练框架应运而生。它通过数据并行、模型并行和流水线并行等技术,有效分解了计算任务,显著提升了训练效率。
核心技术
- 数据并行:将数据拆分到多个GPU上,每个GPU独立计算梯度,最后合并更新模型参数。
- 模型并行:将模型网络拆分到多个GPU上,每个GPU负责部分网络层的计算。
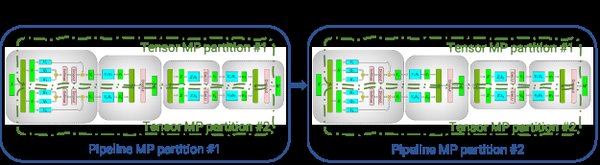
- 流水线并行:将模型的不同层分配到不同的GPU上,通过流水线方式依次计算,减少等待时间。
算力需求与优化
- 计算规模:训练GPT-3需数千块GPU,消耗数万GPU小时。
- 精度要求:采用混合精度训练(FP16/FP32),兼顾速度与稳定性。
- 内存压力:大模型参数量大,需分布式训练(如Megatron-LM)。
- 能源消耗:单次训练碳排放可达数百吨,能源需求巨大。
Megatron在模型推理中的应用
与训练相比,推理阶段的算力需求较低,但实时性和能效比成为关键。Megatron通过模型量化和硬件加速等技术,优化了推理性能。
优化技术
- 模型量化:将FP32模型转为INT8,减少内存占用和计算量。
- 硬件加速:专用AI芯片(如TPU、华为昇腾)提升吞吐量。
- 动态批处理:合并多个请求同时计算,提高GPU利用率。


训练与推理的关键差异
| 维度 | 训练 | 推理 |
|---|---|---|
| 算力消耗 | 极高(需反向传播+参数更新) | 较低(仅前向计算) |
| 硬件需求 | 大规模GPU/TPU集群 | 边缘设备、专用AI芯片 |
| 精度要求 | 混合精度(FP16/FP32) | 低精度量化(INT8/FP16) |
| 延迟容忍度 | 可接受数天至数周 | 通常需毫秒至秒级响应 |
未来趋势与展望
随着芯片技术(如Chiplet、光子计算)和算法优化(如MoE模型)的发展,Megatron在训练与推理中的效率差距将进一步缩小,推动AI普惠化。未来,训练-推理一体化、端侧训练和绿色AI等趋势将引领AI技术的发展。
行业趋势
- 训练-推理一体化:动态微调(Online Learning)支持模型在推理中持续学习。
- 端侧训练:联邦学习(Federated Learning)在手机等设备上分布式训练,保护隐私。
- 绿色AI:通过模型剪枝、稀疏训练降低能耗,如Google的Pathways架构。
总结而言,Megatron作为AI大模型训练与推理的核心技术,通过分布式训练和优化推理性能,显著提升了AI模型的效率和可应用性,为AI技术的普及和落地提供了强有力的支持。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。