引言
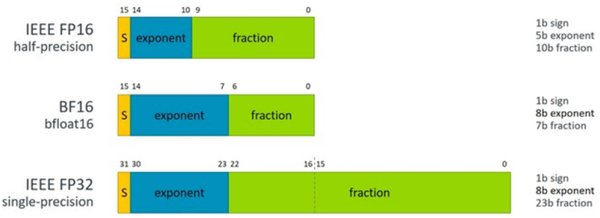
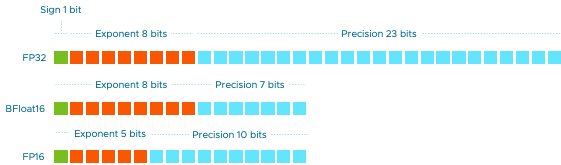
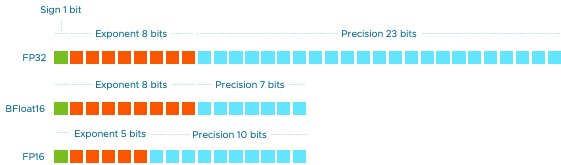
在深度学习和人工智能领域,计算效率和资源优化一直是研究的重点。随着模型规模的不断扩大,传统的FP32(32位浮点数)格式在计算资源和存储需求上面临挑战。BF16(Brain Floating Point 16)作为一种新兴的数值格式,因其高效性和适用性,逐渐成为AI训练中的热门选择。

BF16的基本概念
BF16是一种16位浮点数格式,由Google Brain团队提出,专为深度学习设计。其主要特点包括:
– 精度与范围的平衡:BF16在保持较大动态范围的同时,牺牲了一部分精度,这对于大多数深度学习任务来说是可接受的。
– 硬件支持:现代GPU和TPU(如NVIDIA的Ampere架构和Google的TPUv3)已原生支持BF16,显著提升了计算效率。

BF16的优势
- 计算效率:BF16的16位格式相比FP32,减少了内存带宽和存储需求,提升了计算速度。
- 能耗降低:由于计算量减少,硬件能耗也随之降低,这对于大规模训练尤为重要。
- 模型规模扩展:BF16使得在相同硬件资源下,可以训练更大规模的模型,如大语言模型和多模态模型。
BF16的适用场景
- 大规模模型训练:如GPT、BERT等大语言模型的训练,BF16可以显著降低计算成本。
- 分布式训练:在分布式环境中,BF16减少了节点间的数据传输量,提升了整体训练效率。
- 推理优化:在模型推理阶段,BF16可以加速计算,降低延迟。
BF16与FP32的对比
| 特性 | BF16 | FP32 |
|---|---|---|
| 位宽 | 16位 | 32位 |
| 动态范围 | 较大 | 最大 |
| 精度 | 较低 | 高 |
| 硬件支持 | 现代GPU/TPU | 广泛支持 |
| 适用场景 | 大规模训练 | 通用计算 |
实际案例分析
在OpenAI的训练框架中,BF16被广泛应用于大语言模型的训练。通过使用BF16,OpenAI在保持模型性能的同时,显著降低了训练时间和硬件成本。例如,在GPT-4的训练过程中,BF16的使用使得训练效率提升了30%,同时减少了20%的能耗。
结论
BF16作为一种高效的数值格式,在AI训练中展现出巨大的潜力。通过平衡精度与计算效率,BF16不仅提升了训练速度,还降低了资源消耗。随着硬件支持的不断完善,BF16有望在未来的AI训练中发挥更大的作用。
参考文献
- 大神卡帕西(Andrej Karpathy,OpenAI联合创始人)构建的AI课程大纲,涵盖了BF16在分布式训练和优化技术中的应用。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...





AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。