Transformer架构:大语言模型的技术基石
2017年,Vaswani等人提出的Transformer架构彻底改变了自然语言处理(NLP)领域。与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,Transformer通过自注意力机制实现了并行计算和全局上下文理解,解决了长程依赖性和计算效率低下的问题。
自注意力机制的核心创新
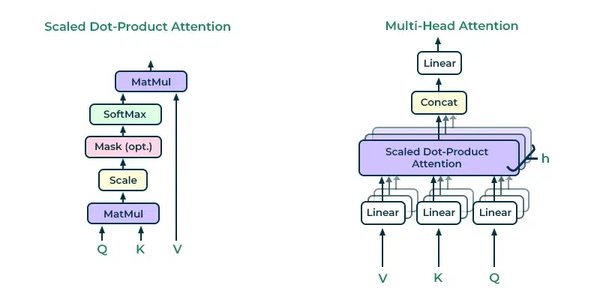
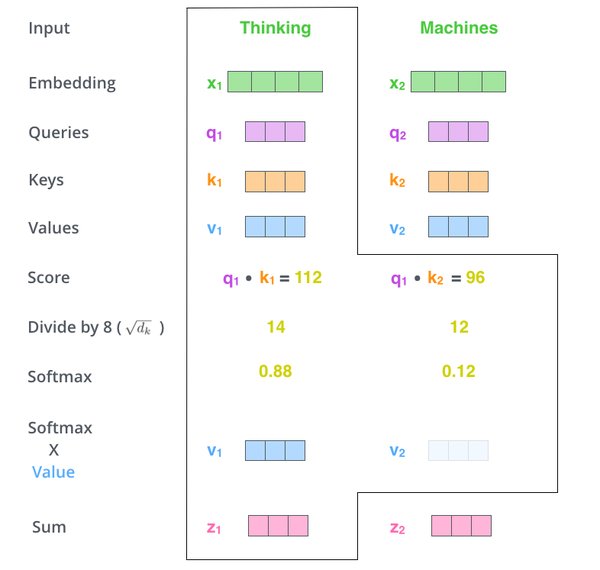
Transformer的核心创新在于自注意力机制,它能够动态权衡每个标记相对于其他标记的重要性。这种机制不仅提高了模型的上下文理解能力,还显著加快了训练速度。具体来说,自注意力机制通过查询(Query)、键(Key)和值(Value)矩阵计算每个标记的权重,从而实现并行化处理。
此外,多头注意力机制进一步增强了模型的表达能力。每个注意力头专注于输入的不同方面,最终通过连接和转换输出,生成更丰富的上下文表示。

从Transformer到GPT与BERT:大语言模型的崛起
Transformer架构的引入为大规模预训练模型铺平了道路。2018年,OpenAI推出了GPT(Generative Pre-trained Transformer),采用自回归训练方式,专注于文本生成任务。同年,谷歌发布了BERT(Bidirectional Encoder Representations from Transformers),通过双向训练方法显著提升了语言理解能力。
GPT系列的演进
GPT系列模型通过不断扩展参数量和优化训练策略,逐步实现了从文本生成到复杂推理任务的跨越。GPT-3凭借1750亿参数,展示了少样本和零样本学习的强大能力,成为大语言模型的里程碑。
BERT的双向训练优势
BERT通过掩码语言建模(MLM)和下一句预测(NSP)任务,能够同时捕捉前后文的语义信息。这一创新使其在文本分类、问答系统等任务中表现出色,奠定了预训练模型在NLP领域的主导地位。

DeepSeek-R1:成本高效与推理能力的突破
2025年初,DeepSeek推出的DeepSeek-R1模型标志着大语言模型在成本效率和推理能力上的重大突破。该模型采用专家混合(MoE)架构和多标记预测(MTP)技术,显著降低了训练和推理成本,同时提升了复杂任务的表现。
DeepSeek-R1的技术创新
DeepSeek-R1通过基于规则的强化学习方法(GRPO)优化训练过程,完全消除了监督微调阶段,直接从预训练模型开始。其蒸馏版模型进一步降低了硬件需求,使得先进推理能力得以在更广泛的场景中应用。
大语言模型的应用与挑战
大语言模型在自动化、内容生成和客户体验优化等方面展现了巨大价值。然而,其开发成本高、隐私安全风险以及潜在的偏见问题仍是亟待解决的挑战。
应用场景
-
自动化:LLM可用于自动化客服、文档生成等任务,提升效率。
-
生成见解:通过分析海量数据,LLM能够生成有价值的业务洞察。
-
客户体验:个性化推荐和对话式AI改善了用户交互体验。
挑战与局限性
-
开发成本:训练大规模模型需要巨额计算资源和数据。
-
隐私与安全:LLM可能泄露敏感信息或生成有害内容。
-
偏见问题:模型可能继承训练数据中的偏见,导致不公平决策。
结语
从Transformer架构的引入到DeepSeek-R1的推出,大语言模型的演进不仅推动了AI技术的发展,也为各行各业带来了深远影响。未来,随着技术的不断进步,LLM将在更多领域展现其潜力,同时也需要在伦理和安全方面进行更深入的探索。







