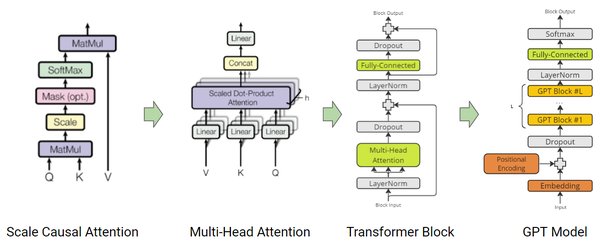
Transformer架构与大语言模型的局限
Transformer架构自2017年由Google提出以来,已成为自然语言处理(NLP)领域的基石。它通过自注意力机制和多头注意力层,能够高效处理长距离依赖关系,广泛应用于机器翻译、文本生成等任务。然而,尽管Transformer在语言模型(如GPT系列)中取得了显著成功,Meta首席AI科学家杨立昆对其能否实现通用人工智能(AGI)持怀疑态度。
杨立昆指出,大语言模型(LLMs)如GPT-4和ChatGPT,尽管在文本生成和对话任务中表现出色,但其核心仍然是基于概率分布的文本生成,而非真正的语义理解。LLMs通过海量数据训练,学习词语之间的统计关系,但缺乏对物理世界的直观理解。这种“表面化”的智能与人类的理解能力有本质区别。例如,LLMs可以生成一段关于“如何修理汽车”的文本,但它并不理解汽车的实际结构或修理的具体操作。
联合嵌入预测架构(JEPA):实现人类级智能的新范式
为了克服LLMs的局限,杨立昆提出了联合嵌入预测架构(JEPA)。JEPA通过自监督学习,从无标注数据中生成伪标签,训练模型在抽象的表示空间中进行预测。这种架构与人类大脑处理信息的模式极为相似,能够捕捉到世界的结构和动态信息,而无需依赖硬编码的抽象表示。
JEPA的核心在于其编码器和预测器的联合训练。编码器从视频中提取特征信息,预测器则基于损坏的视频表征来预测原始视频的表征。通过这种方式,JEPA能够在无需特定任务训练的情况下,展现出对直观物理的理解能力。例如,Meta的V-JEPA模型在分辨符合物理定律与违反物理定律的视频方面,展现出了极高的准确性与一致性。
视觉学习的重要性与未来突破
杨立昆强调,视觉学习是实现人类级智能的关键。人类通过观察、聆听、嗅闻、触等多感官体验来理解世界,而当前的AI系统在视觉理解方面仍存在巨大挑战。莫拉维克悖论指出,对生物体而言轻而易举的任务(如开车、整理房间),对AI来说却极为困难。
杨立昆预测,在未来5-7年内,视觉学习领域可能会有重大突破,10年内可能实现人类级智能。他认为,通过多模态学习(如图像、声音、触觉等),AI将能够更好地理解复杂的人类环境,并解决多样化的任务。例如,OpenAI的多模态模型GPT-4o和o1,已能够处理图像、语音等多模态内容,展现出强大的上下文理解能力。
工程优化与开源策略:DeepSeek的创新路径
在AI模型的工程优化方面,DeepSeek通过创新算法和硬件优化,实现了低成本高性能的目标。其基于Transformer架构的MoE(专家混合模型)和MLA(多头潜在注意力)算法,显著降低了算力和内存需求,提升了推理效率。DeepSeek的开源策略,不仅为行业提供了参考和学习的机会,也推动了整个开源生态的发展。
DeepSeek的成功表明,通过精细的工程优化和开放协作,AI技术可以更加普惠化,降低技术门槛,使更多中小企业和个体开发者能够触及先进的AI技术。这种路径为全球AI生态带来了新的活力和可能性。
结语
Transformer架构在AI领域取得了巨大成功,但其局限性也日益显现。杨立昆提出的联合嵌入预测架构(JEPA)和视觉学习的重要性,为AI的未来发展提供了新的方向。DeepSeek的工程创新和开源策略,则为AI技术的普惠化树立了新的标杆。未来,随着技术的不断突破和生态的日益完善,AI有望实现人类级智能,为人类社会带来深远的影响。



