引言
强化学习(Reinforcement Learning, RL)作为机器学习的重要分支,近年来在人工智能领域取得了显著进展。特别是基于人类反馈的强化学习(RLHF)和基于AI反馈的强化学习(RLAIF),已经成为提升大语言模型(LLM)性能和可信度的关键技术。本文将深入探讨RLHF的技术原理、应用场景及其未来发展方向。
RLHF的技术原理
什么是RLHF?
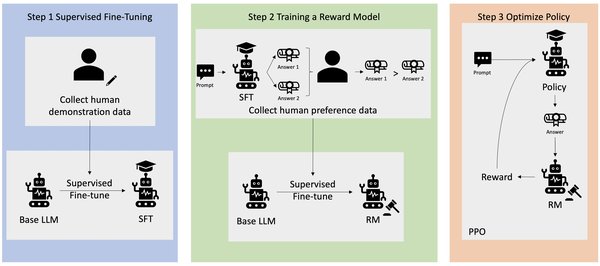
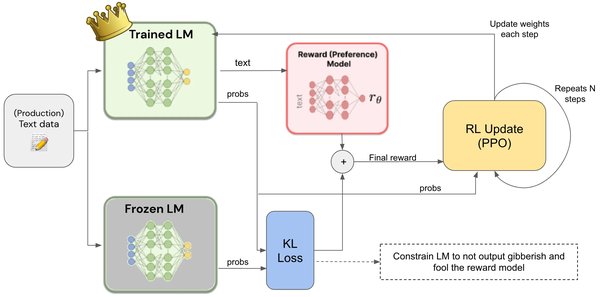
RLHF是一种通过人类反馈来指导模型学习的强化学习技术。其核心思想是让模型在与环境交互的过程中,根据人类提供的奖励信号来优化其行为策略。具体步骤如下:
- 数据收集:通过人类标注或众包模式收集反馈数据。
- 奖励模型训练:利用收集到的反馈数据训练一个奖励模型,用于评估模型输出的质量。
- 策略优化:使用强化学习算法(如PPO)优化模型策略,使其输出的结果更符合人类期望。
RLHF的应用场景
RLHF在大语言模型中的应用主要体现在以下几个方面:
- 减少幻觉:通过人类反馈,模型能够更准确地识别和纠正错误信息,减少“幻觉”现象。
- 提升可解释性:RLHF使得模型的决策过程更加透明,用户可以通过反馈机制了解模型的推理路径。
- 个性化定制:根据不同用户的需求和偏好,模型可以通过RLHF进行个性化调整,提供更符合用户期望的输出。
RLAIF:从人类反馈到AI反馈
RLAIF的定义
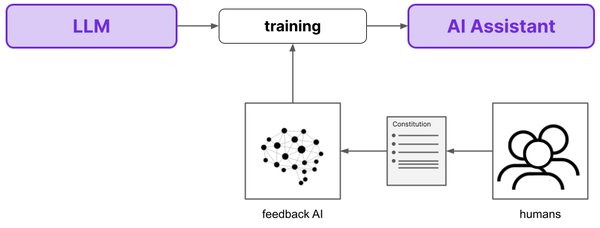
RLAIF是一种基于AI反馈的强化学习技术,它利用AI模型自身的反馈来指导学习过程。与RLHF相比,RLAIF具有以下优势:
- 自动化程度高:无需大量人类标注,AI模型可以自动生成反馈数据。
- 成本效益显著:减少了人类标注的成本,提高了训练效率。
- 可扩展性强:适用于大规模模型训练,能够快速迭代和优化。
RLAIF的实际案例
以DeepSeek的R1模型为例,其通过RLAIF技术实现了以下突破:
- 自主推理能力:R1模型能够自主生成推理路径(Chain of Thought, CoT),无需人类标注的监督数据。
- 跨领域应用:R1不仅在数学和编程领域表现出色,还在语言生成和风格模仿方面取得了显著进展。
- 透明性与可解释性:DeepSeek通过开源模型和详细的技术文档,使得R1的推理过程更加透明,为其他团队提供了可复制的成功经验。
RLHF与RLAIF的未来展望
技术融合与创新
未来,RLHF和RLAIF有望在以下方面实现进一步融合与创新:
- 多模态学习:结合图像、音频等多模态数据,提升模型的理解和生成能力。
- 实时反馈机制:开发实时反馈系统,使模型能够根据用户反馈进行动态调整。
- 跨领域协同:通过开源社区和众包模式,推动RLHF和RLAIF在不同领域的应用和优化。
社会影响与伦理考量
随着RLHF和RLAIF技术的广泛应用,其社会影响和伦理问题也日益凸显:
- 信任与透明性:如何确保模型的决策过程透明,增强用户对AI的信任。
- 数据隐私与安全:在收集和使用人类反馈数据时,如何保护用户隐私和数据安全。
- 公平性与包容性:确保模型在不同文化、语言和背景下的公平性和包容性。
结论
从人类反馈到AI反馈,强化学习正在重塑AI的未来。RLHF和RLAIF作为关键技术,不仅在提升模型性能和可信度方面发挥了重要作用,还为AI的跨领域应用和社会影响提供了新的思路。未来,随着技术的不断进步和应用的深入,RLHF和RLAIF有望在更多领域实现突破,推动AI技术的持续发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...






AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。