强化学习基础:从值函数到策略梯度
强化学习(Reinforcement Learning, RL)是机器学习的一个重要分支,其核心思想是通过智能体与环境的交互来学习最优策略。值函数和策略梯度是强化学习的两个基本概念:
-
值函数:用于评估某个状态或状态-动作对的长期收益,包括状态值函数(V函数)和动作值函数(Q函数)。
-
策略梯度:直接优化策略参数,通过梯度上升法最大化期望收益。
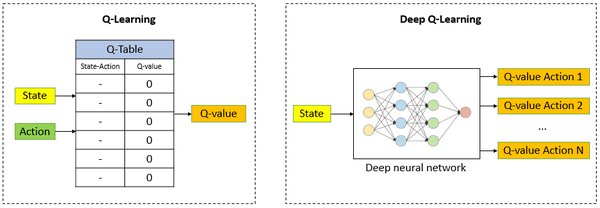
DQN:深度强化学习的里程碑
深度Q网络(Deep Q-Network, DQN)是强化学习领域的重要突破,它将深度学习与Q学习相结合,解决了传统Q学习在高维状态空间中的局限性。DQN的核心改进包括:
-
经验回放:通过存储和随机采样历史数据,打破数据相关性,提高学习效率。
-
目标网络:使用独立的网络计算目标Q值,减少训练过程中的不稳定性。
改进算法:从DQN到PPO
在DQN的基础上,研究者提出了多种改进算法,以解决其局限性并提升性能:
-
Double DQN:减少Q值的高估问题,提高算法稳定性。
-
PPO(Proximal Policy Optimization):通过限制策略更新的幅度,确保训练过程的稳定性,适用于连续动作空间。
实例解析:棋类游戏中的强化学习
强化学习在棋类游戏中的应用是理解其原理的绝佳案例。例如,在RTDP(Real-Time Dynamic Programming)中,每个棋局位置都有一个固定评分,可能导致算法忽略某些潜在的高收益路径。而MCTS(Monte Carlo Tree Search)通过每次运行时的全新模拟,能够更灵活地发现最优策略,不受初始评分的影响。
强化学习的实际应用
强化学习不仅在游戏中表现出色,还在实际场景中广泛应用:
-
推荐系统:如网飞(Netflix)通过强化学习优化用户推荐,提升用户体验。
-
机器人控制:通过强化学习训练机器人完成复杂任务,如抓取和导航。
总结
强化学习通过智能体与环境的交互,逐步学习最优策略。DQN及其改进算法在解决高维状态空间和连续动作空间问题上展现了强大的能力。结合棋类游戏和实际应用案例,本文希望帮助读者深入理解强化学习的核心原理与实现方法。





