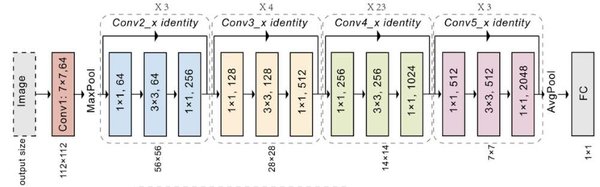
ResNet50:深度学习中的里程碑
ResNet50作为一种深度卷积神经网络架构,凭借其50层的深度和残差块设计,成功解决了深度网络训练中的梯度消失问题。其核心特点包括:
-
残差块:通过捷径连接,输入直接传递到输出,使得网络能够学习残差映射,提升训练效率。
-
瓶颈架构:利用1×1卷积层减少滤波器数量,降低计算成本,提升特征提取效率。
-
批归一化:加速训练过程,提高训练稳定性。
ResNet50在ImageNet数据集上训练,参数数量约为2560万,广泛应用于图像分类、目标检测等计算机视觉任务。

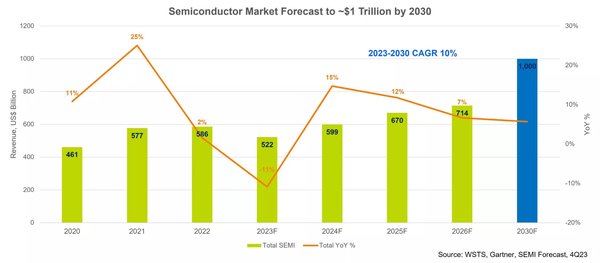
AI算力需求与半导体市场变革
AI技术的快速发展对算力提出了前所未有的需求。以英伟达H100 GPU为例,训练GPT-4级大模型需要2.5万片H100集群运行90天,耗电量相当于3.6万户家庭年用电量。这种指数级增长的算力需求,直接推动了半导体市场的深刻变革:
-
市场规模:全球半导体市场预计到2030年突破1.51万亿美元,AI加速器芯片市场规模预计2025年突破1500亿美元。
-
技术创新:台积电、三星、英特尔进入2nm量产阶段,晶体管密度提升50%,功耗降低30%。
-
存储芯片:高带宽内存(HBM)需求激增,2025年市场规模预计达270亿美元。

华为昇腾910B:国产芯片的崛起
在AI算力竞赛中,华为昇腾910B展现了国产芯片的强劲实力:
-
训练速度:在ResNet50训练速度上比英伟达H100快了17%。
-
推理能耗:比H100低了23%。
-
适配程度:适配国产框架的程度高达92%。
华为在制裁下将昇腾910B的7nm良品率提升到89%,中芯国际的N+2工艺月产能达到5万片,标志着国产半导体在AI浪潮中的局部突围。
AI驱动下的半导体产业链变革
AI技术的深入应用,正在重构半导体产业链的竞争力:
-
材料革命:碳化硅(SiC)功率器件在AI服务器电源模块中渗透率超40%,供电效率提升至98%。
-
封装进化:台积电SoIC技术实现1μm级凸点间距,使chiplet互连密度提升10倍。
-
设计范式迁移:谷歌TPU v5采用稀疏计算架构,动态屏蔽零权重,提升训练速度。
未来展望:AI算力的三浪叠加
AI对半导体产业的改造将呈现“三浪叠加”特征:
-
第一浪(2025-2027):以ChatGPT级大模型训练需求为主导,HBM、CoWoS封装、3nm以下制程成为竞争焦点。
-
第二浪(2028-2030):边缘AI设备普及带动存算一体芯片爆发,车规级AI芯片渗透率超60%。
-
第三浪(2030+):量子计算与神经形态芯片商用化,彻底重构算力供给体系。
在这场跨越十年的技术长征中,ResNet50作为AI算力竞赛的核心引擎,将继续推动半导体行业的技术创新与市场增长,迎接“算力定义文明”的新纪元。






