
GPT-4.5:AI模型的新里程碑
OpenAI近日发布了GPT-4.5大模型的预览版本,这是其迄今为止最大、知识最丰富的模型。GPT-4.5在交互、知识面、情商及多领域能力上均有显著提升,尤其是在SimpleQA基准测试中表现优异。该模型目前已经向每月订阅费用200美元的ChatGPT Pro用户开放,并计划在下周向每月20美元的ChatGPT Plus订阅用户开放。

SimpleQA基准测试表现
SimpleQA基准测试主要考察AI在处理简单、事实性问题时的准确度。根据OpenAI的测试结果,GPT-4.5在这一测试中的表现优于其前代模型GPT-4o和OpenAI的推理模型o1、o3-mini。这一结果表明,GPT-4.5在处理基础信息时具有更高的准确性和可靠性。
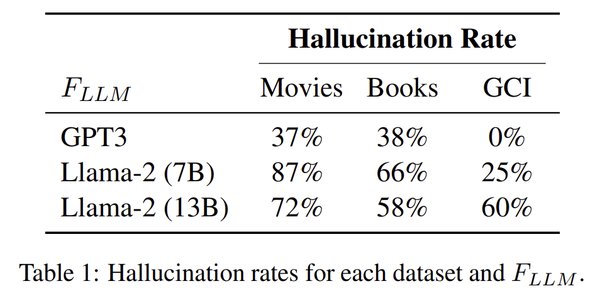
情商提升与幻觉率降低
GPT-4.5在情商方面也有显著提升。例如,在面对“我考试失败了,心情很低落”这样的输入时,GPT-4.5会先询问用户是否想聊聊这个问题,还是需要一些分散注意力的方法。这种回应显示出更高的情感智能。此外,GPT-4.5的“幻觉率”——即AI系统生成不准确信息的概率——为37%,相比其前代模型GPT-4o的60%有显著降低。
多领域能力提升
GPT-4.5在多个领域的表现也令人瞩目。在编程能力方面,GPT-4.5在SWE-Bench Verified基准测试上与GPT-4o和o3-mini表现相当,但在SWE-Lancer编程测试上超过了这两个模型。在数学和科学相关问题上,GPT-4.5的表现仍然处于领先水平,与其他非推理模型相比表现更优。
未来展望
尽管GPT-4.5在多模态功能上仍有局限,但其在SimpleQA基准测试和其他领域的优异表现,标志着OpenAI在AI模型开发上的新里程碑。未来,OpenAI计划在今年晚些时候发布GPT-5,将把GPT系列模型与o系列模型结合,构建能够自主判断需要思考多久再生成回答的AI系统。这一目标是为了简化用户体验,让用户不必在越来越复杂的选项列表中进行选择。
GPT-4.5的发布不仅展示了OpenAI在AI模型开发上的技术实力,也为未来的AI应用提供了更多的可能性。







