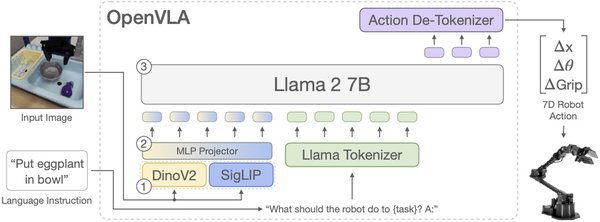
VLA模型的技术本质与核心优势
VLA模型(视觉-语言-动作模型)在自动驾驶领域展现出显著优势,尤其在可解释性、泛化性及复杂场景适应性方面。相较传统模块化方案与初代端到端技术,VLA模型通过视觉编码器提取图像的高级特征,文本编码器处理用户指令或导航信息,轨迹解码器输出未来10-30秒的驾驶路径,而文本解码器则解释决策原因。例如,在潮汐车道场景中,VLA模型可通过读取标志、分析上下文并与其他车辆交互,完成安全变道,并清晰说明每一步原因。
VLA模型的行业布局与竞争格局
元戎启行、理想汽车等企业已明确布局VLA模型,Wayve等国际玩家也在同步推进,而小鹏、华为等头部车企或将快速跟进。预计2025年中旬,随着首批VLA车型亮相,国内智驾竞争将全面“开卷”,从技术储备转向用户体验与市场渗透的较量。VLA模型的兴起还伴随着行业逻辑的转变,作为“端到端2.0”,VLA模型继承了无图化与神经网络的优点,还通过语言推理填补了可解释性空白,恰逢自动驾驶洗牌期,行业正加速向通用AI靠拢。
VLA模型的未来潜力
在技术迭代加速与市场竞争加剧的背景下,VLA模型的兴起不仅重塑了智能驾驶的技术逻辑,也为未来出行方式的定义提供了全新可能。竞争格局下,数据与算力成为胜负手。中国市场独特的道路复杂性与高密度交通为VLA模型提供了天然“试验场”,但也对数据质量提出更高要求。国内企业若能利用本土优势,快速迭代VLA模型,或将在全球竞争中占据先机。
结论
VLA模型在自动驾驶领域的应用前景广阔,尤其在可解释性、泛化性及复杂场景适应性方面展现出显著优势。随着技术的不断迭代和市场的逐步成熟,VLA模型有望成为自动驾驶的“最终归宿”。然而,数据与算力的竞争仍将是未来发展的关键,国内企业需充分利用本土优势,快速迭代,以在全球竞争中占据先机。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...




AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。