Mistral 8x7B:开源的稀疏混合专家模型
Mistral AI最新发布的Mixtral 8x7B模型,是一款基于稀疏混合专家架构(Sparse Mixture of Experts, SMoE)的开源语言模型。这款模型不仅在性能上超越了Llama 2 70B和GPT-3.5,还通过其独特的设计大幅降低了计算成本,成为AI领域的一大亮点。
稀疏混合专家架构的核心优势
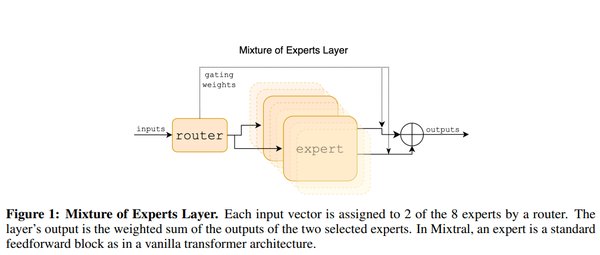
Mixtral 8x7B的核心在于其稀疏混合专家架构。与传统模型不同,稀疏混合专家模型通过路由器机制,每次仅激活与输入最相关的2个专家模块。这种设计使得模型在处理每个Token时,仅使用129亿个参数,而非全部467亿个参数。这不仅显著降低了计算成本,还大幅提升了处理效率。
性能表现:超越Llama 2 70B和GPT-3.5
在多项基准测试中,Mixtral 8x7B的表现均优于Llama 2 70B,推理速度更是后者的6倍。与GPT-3.5相比,Mixtral 8x7B在大多数任务中表现相当甚至更优,尤其是在减少“幻觉”和偏见方面表现突出。此外,其微调版本Mixtral 8x7B Instruct在MT-Bench测试中获得8.3分,成为目前最佳的开源指令跟随模型。
多语言支持与代码生成能力
Mixtral 8x7B支持多种语言,包括英语、法语、意大利语、德语和西班牙语,并在代码生成任务中表现出色。这使得它不仅适用于通用语言任务,还能在特定领域(如编程辅助)中发挥重要作用。
硬件需求与优化方案
尽管Mixtral 8x7B的性能卓越,但其对显存(VRAM)的需求较高,普通消费级GPU难以直接运行。通过量化技术(如Q3_K_M和Q5_K_M),可以在降低显存占用的同时保持较高的模型质量。例如,使用两张3060 Ti 12GB显卡组成的36GB VRAM方案,可以高效运行高精度版本的Mixtral 8x7B。
开源的未来
Mixtral 8x7B采用Apache 2.0开源协议,为开发者和研究者提供了极大的灵活性。其开源特性不仅推动了AI技术的普及,也为后续的优化和创新提供了坚实基础。

结语
Mixtral 8x7B凭借其稀疏混合专家架构、卓越的性能表现和开源特性,成为AI领域的一大突破。无论是学术研究还是商业应用,这款模型都展现出了巨大的潜力,为未来的AI发展开辟了新的方向。








