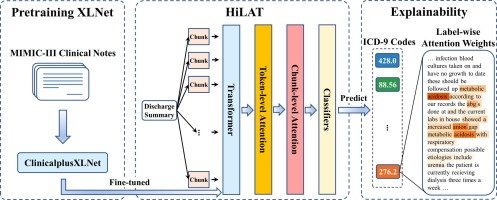

分层注意力机制的起源与发展
分层注意力机制是大语言模型(LLM)中的一项核心技术,其起源可追溯到2014年提出的“注意力机制”(Attention Mechanism)。这一技术旨在模拟人类认知注意力的方式,通过深度学习在庞大的数据集上进行训练,从而理解和生成文本。2017年,《Attention Is All You Need》论文的发表标志着Transformer模型的诞生,进一步优化了注意力机制,引发了AI领域的变革。
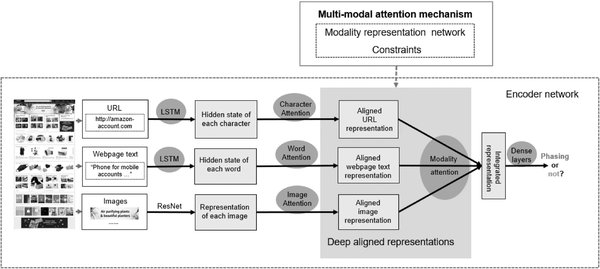
分层注意力机制的核心优势
分层注意力机制的核心优势在于其能够分层处理语言特征,基础层处理语言通用特征,专业层适配法律、金融等垂直领域。这种分层处理方式使得模型在多语言理解、文本生成和垂直领域适配中表现出色。例如,Cohere最新推出的Command R+模型通过分层注意力机制,在处理欧盟多语种合同时,能够自动识别28国法律差异,同步生成合规条款的本地化版本。
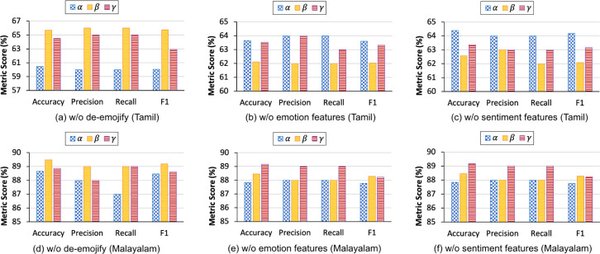
分层注意力机制在多语言理解中的应用
分层注意力机制在多语言理解中的应用尤为突出。Cohere的Command R+模型支持128k上下文窗口的跨语言理解能力,在处理混合语言输入时,意图识别准确率较传统方案提升37%。这一突破性技术通过动态知识蒸馏机制,实时抽取目标区域社交媒体数据构建文化禁忌库,使合规文本生成准确率突破99%。
分层注意力机制的未来发展趋势
随着AI技术的不断演进,分层注意力机制将在以下几个方面取得突破:
-
更强的推理与创造能力:未来的分层注意力机制可能更接近人类的逻辑思维水平,甚至能够独立研究科学问题。
-
更高效的本地运行能力:开源轻量级LLM将使个人设备也能运行强大的AI。
-
更安全、更可控的AI:通过Constitutional AI和强化学习,未来的分层注意力机制将更符合道德与安全标准。
结论
分层注意力机制作为大语言模型中的核心技术,正在推动AI技术的革新。通过分层处理语言特征,分层注意力机制在多语言理解、文本生成和垂直领域适配中展现出巨大潜力。未来,随着计算能力的提升和数据训练方法的优化,分层注意力机制将在更多领域发挥重要作用,为全球化商业运作提供智能基座。