DeepSeek-R1:开源模型的推理能力突破
DeepSeek-R1是一款开源的6710亿参数混合专家(MoE)模型,专为解决需要高级AI推理的复杂问题而设计。该模型通过强化学习(RL)技术进行训练,擅长逻辑推理、多步问题解决和结构化分析。DeepSeek-R1在多个推理基准测试中表现出色,特别是在GPQA Diamond测试中,展现了其在生物学、物理学和化学领域的强大推理能力。
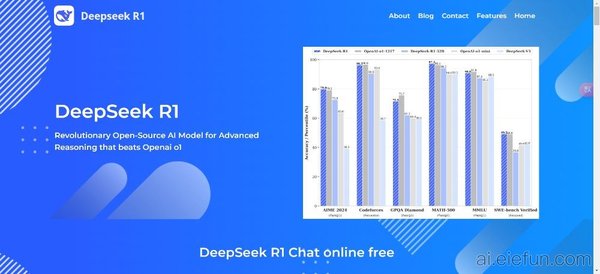

GPQA Diamond测试中的表现
GPQA Diamond是一组由专家验证的多项选择题,涵盖了生物学、物理学和化学等多个学科。DeepSeek-R1在这一测试中表现出色,其推理能力接近甚至超越了闭源模型。通过量化技术,DeepSeek-R1在保持高准确率的同时,显著提升了推理速度,使其在实际应用中更加高效。
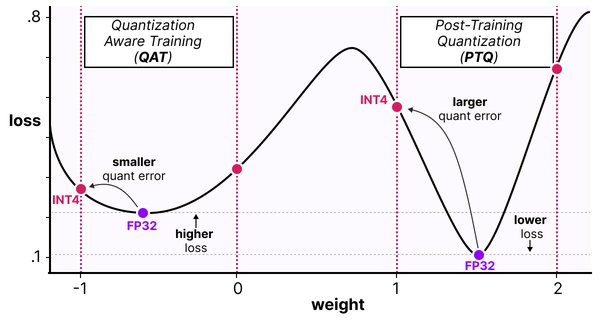
量化模型的优势
量化技术是DeepSeek-R1的一大亮点。通过FP8和INT8量化,模型在推理速度上实现了显著提升,同时保持了接近原始模型的准确率。例如,在GPQA Diamond测试中,量化后的DeepSeek-R1模型在推理速度上提升了1.4倍,而准确率仅略有下降。这种技术在AI普及化中具有重要意义,因为它降低了计算成本和硬件门槛,使更多企业和个人能够使用高性能的AI模型。
强化学习与推理能力的结合
DeepSeek-R1的训练过程中,强化学习(RL)技术起到了关键作用。通过RL,模型能够生成更加准确和结构化的推理链,从而在复杂任务中表现出色。例如,在GPQA Diamond测试中,DeepSeek-R1通过多步推理,成功解决了多个专家级难题。这种训练方法不仅提升了模型的推理能力,还使其在实际应用中更加灵活和高效。
开源模型与AI普及化
DeepSeek-R1的开源性质为AI普及化提供了有力支持。通过开源,更多研究者和开发者可以参与模型的优化和扩展,推动AI技术的广泛应用。例如,Tiny-R1-32B-Preview模型在仅使用DeepSeek-R1 5%参数的情况下,便在GPQA Diamond测试中取得了接近完整模型的成绩。这种低成本、高效率的模型训练方式,为AI技术的普及化提供了新的可能性。
结论
DeepSeek-R1在GPQA Diamond等复杂推理测试中的优异表现,展示了开源模型在AI领域的巨大潜力。通过量化技术和强化学习的结合,DeepSeek-R1不仅提升了推理能力,还降低了计算成本,为AI普及化铺平了道路。未来,随着更多开源模型的涌现,AI技术将更加普及,推动各行各业的智能化转型。






