
Cohere Aya Vision:多模态模型的创新者
2025年,Cohere发布了Aya Vision,这是一款支持多模态任务的大型语言模型(LLM)。Aya Vision不仅在多语言支持上表现出色,还在图像理解、文本识别等任务中展现了强大的能力。作为一款开源模型,它为非商业用途提供了灵活的访问方式,用户可以通过Hugging Face、Kaggle或Cohere Playground进行实验。
Aya Vision的核心特性
-
多语言支持:Aya Vision支持23种语言,使其成为全球应用的理想选择。
-
多模态能力:模型能够处理图像、文本和视觉问题,适用于图像描述、OCR(光学字符识别)和视觉问答等任务。
-
开源与非商业许可:采用Creative Commons Attribution Non Commercial 4.0许可,允许用户在非商业场景中自由使用。
-
性能卓越:在AyaVisionBench和m-WildVision基准测试中,Aya Vision 8B版本在多项任务中超越了同类模型,如Qwen2.5-VL 7B和Gemini Flash 1.5 8B。
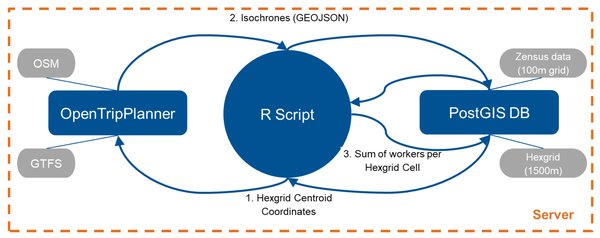
应用场景与性能测试
Cohere Aya Vision在多项测试中展现了其多模态能力的潜力:
-
图像计数:成功识别并统计图像中的硬币数量。
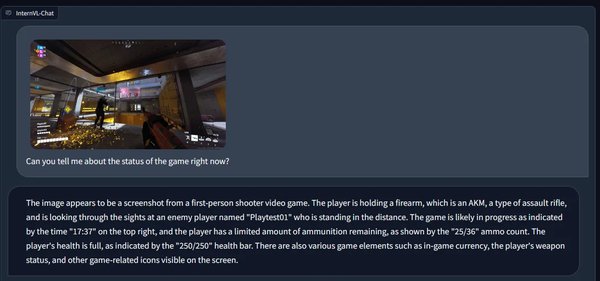
-
视觉问答:准确识别电影场景并描述其内容。
-
文档OCR:尽管在部分任务中表现不稳定,但在菜单价格识别等场景中表现优异。
-
现实世界OCR:在读取序列号等任务中接近完美,仅存在微小误差。
与其他领先模型的对比
Aya Vision与2025年其他热门模型(如OpenAI GPT-4.5和Microsoft Phi-4-multimodal)相比,虽然在复杂推理任务上稍逊一筹,但在多语言和多模态任务中表现突出。例如,GPT-4.5在文档OCR任务中表现更为稳定,而Aya Vision则在多语言支持上占据优势。
未来展望
随着AI领域向推理模型(如OpenAI o3-mini)的转变,Aya Vision的多模态能力为开发者提供了新的可能性。尽管推理模型在复杂任务中表现更优,但Aya Vision的灵活性和开源特性使其在特定场景中具有不可替代的价值。
结语
Cohere Aya Vision的发布标志着多模态大型语言模型的重要进展。无论是多语言支持还是图像理解能力,Aya Vision都为开发者提供了强大的工具。如果您正在寻找一款灵活且高效的多模态模型,Aya Vision无疑是一个值得关注的选择。






