什么是Silhouette Score?
Silhouette Score是一种用于评估聚类算法(尤其是K-means聚类)质量的指标。它通过量化每个数据点在其所属簇中的紧密程度以及与其他簇的分离程度,为聚类结果提供了直观的评估。Silhouette Score的取值范围为-1到1,得分越接近1,表示数据点聚类效果越好;得分接近-1,则可能意味着数据点被错误地分配到了其他簇。

Silhouette Score的计算方法
Silhouette Score的计算公式如下:
[ s(i) = \frac{b(i) – a(i)}{\max(a(i), b(i))} ]
其中:
– ( a(i) ):数据点( i )到其所属簇中其他点的平均距离。
– ( b(i) ):数据点( i )到最近簇中所有点的平均距离。
通过计算所有数据点的平均Silhouette Score,可以评估聚类模型的整体性能,并帮助确定最佳的簇数量。
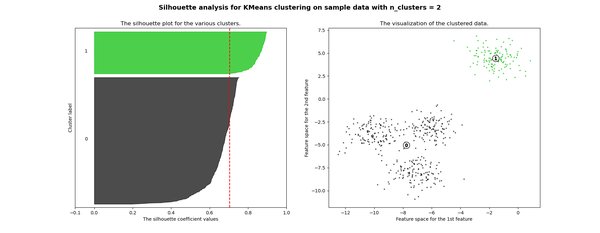
如何可视化Silhouette Score?
Silhouette Plot是Silhouette Score的可视化工具,能够直观地展示每个数据点的聚类效果。以下是使用Python生成Silhouette Plot的示例代码:
“`python
import matplotlib.pyplot as plt
from sklearn.metrics import silhouettesamples, silhouettescore
from sklearn.cluster import KMeans
import numpy as np
生成样本数据
X = np.random.rand(100, 2)
训练K-means模型
kmeans = KMeans(nclusters=3)
kmeans.fit(X)
labels = kmeans.labels
计算Silhouette Score
silhouettevals = silhouettesamples(X, labels)
绘制Silhouette Plot
plt.figure(figsize=(8, 6))
plt.title(‘Silhouette Plot’)
plt.barh(range(len(silhouettevals)), silhouettevals)
plt.xlabel(‘Silhouette Coefficient’)
plt.ylabel(‘Sample Index’)
plt.show()
“`
在Silhouette Plot中,每个条形代表一个数据点,条形的长度表示其Silhouette Score。高分数据点表示聚类效果良好,而低分数据点可能表明聚类存在问题。
Silhouette Score的实用建议
在使用Silhouette Score评估聚类模型时,需注意以下几点:
1. 数据维度:高维数据可能导致距离计算不准确,从而影响Silhouette Score的可靠性。建议使用PCA等降维技术处理高维数据。
2. 簇大小:过小的簇可能导致Silhouette Score不稳定,需确保每个簇包含足够的数据点。
3. 噪声和异常值:噪声和异常值可能扭曲Silhouette Score,因此在进行聚类分析前,应对数据进行预处理。
结论
Silhouette Score是评估K-means聚类模型质量的重要工具,通过其计算和可视化,可以深入分析聚类结果的凝聚性和分离性。掌握Silhouette Score的使用方法,有助于优化聚类策略,提升模型的性能和实用性。