半监督学习与自训练算法
半监督学习作为一种介于监督学习和无监督学习之间的机器学习方法,近年来在学术界和工业界引起了广泛关注。其核心思想是利用少量有标签数据和大量无标签数据进行模型训练,以提高模型性能。自训练算法(Self-Training)是半监督学习中的一种重要方法,尤其适用于分类问题。
自训练算法的核心思想
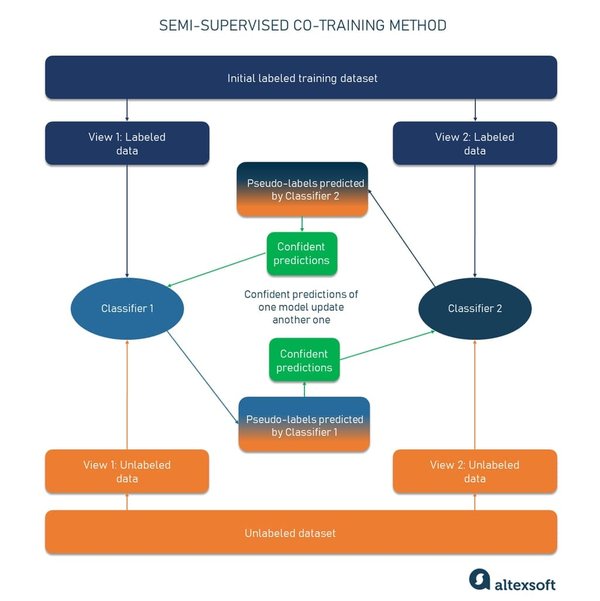
自训练算法的基本流程如下:
- 初始训练:使用少量有标签数据训练一个初始分类器。
- 伪标签生成:利用该分类器对无标签数据进行预测,生成伪标签。
- 样本选择:选择置信度较高的伪标签样本,将其加入训练集。
- 迭代训练:使用更新后的训练集重新训练分类器,并重复上述步骤,直到满足停止条件。
通过这种迭代过程,自训练算法能够逐步提高分类器的性能,充分利用无标签数据中的信息。
自训练算法的优势与挑战
自训练算法的主要优势在于其简单性和高效性。与复杂的半监督学习方法相比,自训练算法易于实现,且在许多实际应用中表现出色。然而,自训练算法也面临一些挑战:
- 错误累积:在迭代过程中,错误的伪标签可能导致模型性能下降。
- 样本选择策略:如何选择高置信度的伪标签样本是关键问题,直接影响算法的效果。
自训练算法的应用场景
自训练算法广泛应用于以下领域:
- 文本分类:在自然语言处理中,自训练算法可用于文本分类任务,如情感分析、主题分类等。
- 图像识别:在计算机视觉领域,自训练算法可用于图像分类、目标检测等任务。
- 生物信息学:在基因表达数据分析中,自训练算法可用于基因功能预测等任务。
未来研究方向
随着半监督学习研究的深入,自训练算法仍有很大的改进空间。未来的研究方向包括:
- 改进样本选择策略:探索更有效的样本选择方法,以减少错误累积。
- 结合其他半监督学习方法:将自训练算法与其他半监督学习方法结合,以进一步提高模型性能。
- 应用于更多领域:探索自训练算法在更多领域的应用,如医疗诊断、金融预测等。
结论
自训练算法作为半监督学习中的一种重要方法,具有广泛的应用前景。通过结合少量有标签数据和大量无标签数据,自训练算法能够显著提升模型性能,是机器学习领域的重要研究方向。未来的研究将继续探索自训练算法的改进方法,以应对更复杂的应用场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...







AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。