随着人工智能和机器人技术的快速发展,视觉传感技术作为多模态感知的核心组成部分,正在推动自动驾驶和具身智能机器人领域的创新突破。本文将从技术原理、应用场景和未来趋势三个维度,深入探讨视觉传感技术的前沿进展。
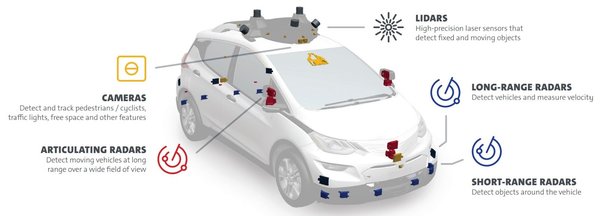
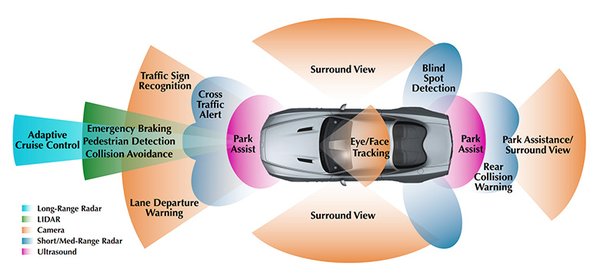
视觉传感技术在自动驾驶中的应用
EMMA模型:多模态感知的典范
Waymo最新发布的EMMA模型是视觉传感技术在自动驾驶领域的杰出代表。EMMA通过将摄像头传感器数据与多模态大语言模型结合,实现了端到端的自动驾驶功能。其技术亮点包括:
– 多模态融合:将图像、文本和导航指令统一处理,生成驾驶轨迹和3D目标检测结果。
– 思维链推理:通过层次化的场景描述和目标行为分析,增强决策的可解释性。
– 通用模型能力:联合训练规划、检测和道路图任务,提升整体性能。
技术局限与改进方向
尽管EMMA在运动规划和目标检测中表现出色,但仍存在以下挑战:
– 帧数限制:只能处理少量图像帧,难以应对复杂动态场景。
– 传感器单一:缺乏激光雷达和雷达等精确3D传感模态。
– 计算成本高:需要优化模型以降低资源消耗。

视觉传感技术在具身智能机器人中的应用
深圳市的具身智能机器人行动计划
深圳市发布的《具身智能机器人技术创新与产业发展行动计划(2025-2027年)》为视觉传感技术提供了广阔的应用场景。重点领域包括:
1. 多模态感知技术:开发高精度视、触、力等多模态传感器。
2. AI芯片研发:支持具身智能端到端大模型和多模态大模型推理加速。
3. 开源数据集构建:利用多模态数据要素,开发真机数据采集平台。
技术突破与产业生态
该计划强调了以下关键目标:
– 核心技术攻坚:突破高能量密度微小电机、类脑视觉传感器等技术。
– 产业生态构建:打造公共服务平台矩阵,吸引上下游企业协同创新。
– 应用场景落地:在工业制造、医疗健康、交通等领域开放50个以上应用场景。
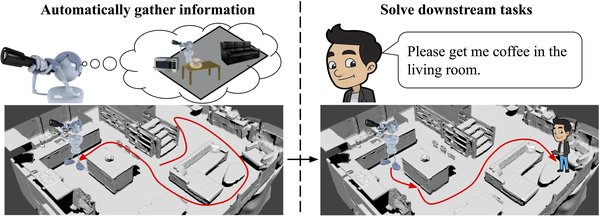

未来趋势与挑战
技术融合与创新
视觉传感技术正朝着以下方向发展:
– 多模态深度融合:整合视觉、触觉、力觉等多种感知模态。
– 边缘计算优化:开发低功耗、高集成度的机器人端侧计算芯片。
– 自主学习能力:构建具备长序列推理和跨场景任务处理能力的智能基座。
产业应用与风险
尽管前景广阔,但仍需关注以下风险:
– 数据隐私与安全:多模态数据采集和应用中的隐私保护问题。
– 技术标准化:缺乏统一的技术标准和评测体系。
– 产业协同:上下游企业间的技术壁垒和合作机制。
视觉传感技术作为人工智能和机器人领域的核心技术,正在重塑自动驾驶和具身智能机器人的未来。通过持续的技术创新和产业协同,视觉传感技术将为智能交通和机器人产业带来更多突破性应用,推动社会生产力的全面提升。










