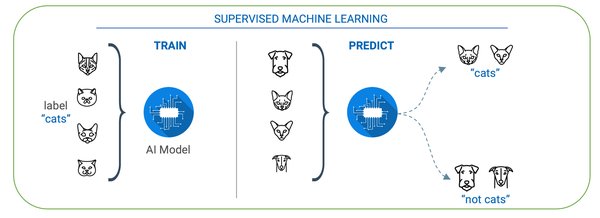
监督学习:数据标签的力量
监督学习是机器学习中最基础且广泛应用的方法之一。其核心在于使用带有标签的数据集进行模型训练,使模型能够通过学习输入与输出之间的关系进行预测。著名的ImageNet数据集便是监督学习的杰出代表,由华人AI科学家李飞飞教授通过众包方式构建,推动了深度学习在视觉领域的应用。监督学习的优势在于其明确的评估机制,通过计算预测与真实标签之间的损失,不断优化模型参数,使其更加精准。
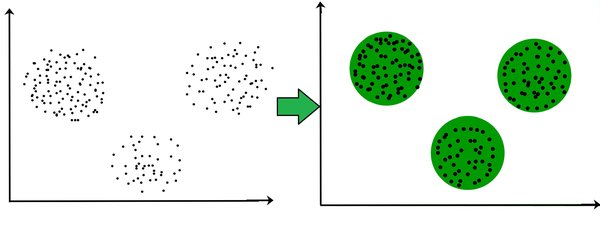

无监督学习:从数据中挖掘潜在规律
与监督学习不同,无监督学习不依赖标签数据,而是通过挖掘数据中的潜在规律进行学习。典型的无监督学习算法包括聚类和主成分分析(PCA)。近年来,无监督学习在大语言模型的发展中发挥了重要作用,例如Google提出的BERT模型,通过自监督学习策略,在自然语言处理领域取得了突破性进展。无监督学习的核心假设包括平滑性假设、聚类假设和流形假设,这些假设为算法的有效性提供了理论支持。
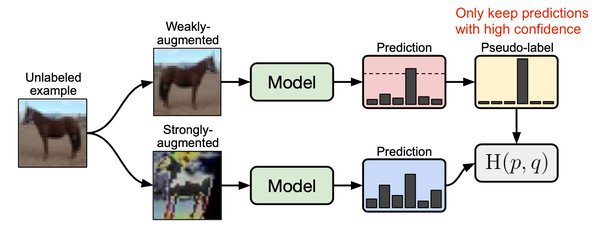
半监督学习:花小钱办大事
半监督学习结合了监督学习和无监督学习的优势,利用少量标签数据和大量未标签数据进行训练。其核心思想是通过对未标签数据生成伪标签,并将其用于监督学习。尽管这种方法看似“离谱”,但其在实际应用中表现出了显著的效果,尤其是在数据标注成本高昂的领域。半监督学习的成功离不开其合理的假设基础,例如相似数据在特征空间中的接近性。
深度学习:模拟人脑的神经网络
深度学习作为机器学习的一个重要分支,通过模拟人脑的神经网络结构,实现了对非结构化数据的自动特征提取。深度学习的崛起得益于硬件算力的提升和算法的创新,例如反向传播训练算法的提出。近年来,深度学习在图像识别、自然语言处理等领域取得了显著成果,例如ChatGPT和DeepSeek等产品的问世,标志着深度学习技术的成熟与广泛应用。
强化学习:试错中的智能进化
强化学习通过智能体与环境的交互进行学习,以最大化累积奖励为目标。与监督学习不同,强化学习没有明确的标签数据,而是通过试错探索最优策略。强化学习的经典应用包括AlphaGo在围棋领域的突破,以及OpenAI提出的RLHF方法,通过人类反馈优化大模型的输出。尽管强化学习的学习效率较低,但其在复杂任务中的表现令人瞩目。
机器学习算法的应用与未来
机器学习算法在分类、回归、聚类和生成式问题中有着广泛的应用。例如,分类问题可用于图像识别,回归问题可用于房价预测,而生成式问题则体现在大模型的文本生成能力中。随着技术的不断发展,机器学习在医疗、教育、金融等领域的应用前景广阔。然而,未来也面临着数据隐私、伦理困境等挑战,需要社会各界共同努力,推动科技与人性的和谐共存。
机器学习算法的优点与缺点
| 算法类型 | 优点 | 缺点 |
|---|---|---|
| 监督学习 | 评估机制明确,预测精度高 | 数据标注成本高昂 |
| 无监督学习 | 无需标签数据,挖掘潜在规律 | 结果解释性较差 |
| 半监督学习 | 结合少量标签数据与大量未标签数据,成本低 | 伪标签可能存在误差 |
| 深度学习 | 自动特征提取,处理非结构化数据能力强 | 训练成本高,模型解释性差 |
| 强化学习 | 适用于复杂任务,探索最优策略 | 学习效率低,训练过程不稳定 |
机器学习算法的演进与应用展现了人工智能技术的无限潜力。未来,随着量子计算、纳米传感器等技术的突破,机器学习将在更多领域发挥重要作用,为人类社会带来深远影响。




