引言
在人工智能领域,模型的性能与成本始终是两大核心议题。DeepSeek-V3作为幻方量化推出的自研MoE(混合专家)模型,凭借其卓越的性能和极低的训练成本,成为了行业关注的焦点。本文将深入探讨DeepSeek-V3的技术创新、行业影响以及未来发展趋势。
DeepSeek-V3的技术创新
模型架构
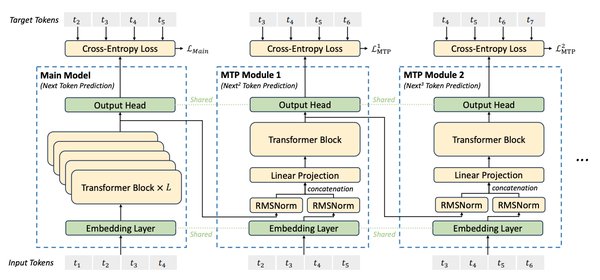
DeepSeek-V3拥有6710亿参数,采用混合专家模型架构,显著提升了模型的推理效率和性能。其关键技术创新包括:
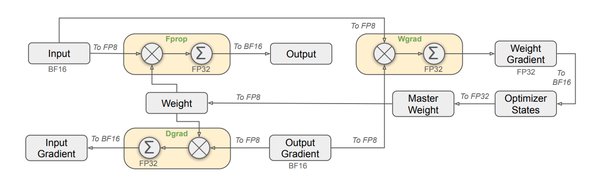
– 多投潜注意力(MLA)算法:显著提升推理效率,使训练成本仅为GPT-4的1/70。
– FP8数据格式:减少显存需求,进一步优化算力利用。
– 动态专家分布:根据用户需求动态调整细粒度专家的分布,提升模型响应速度。
性能表现
DeepSeek-V3在多项基准测试中表现优异,尤其在数学能力方面超越了所有开源和闭源模型。其生成速度相比上一代V2.5提升了3倍,达到60 TPS。

行业影响
算力优化与成本控制
DeepSeek-V3的训练成本极低,仅花费557.6万美元,训练时间不到2个月。其API服务定价上调至每百万输入tokens 0.5元(缓存命中)/2元(缓存未命中),每百万输出tokens 8元,与同类型模型相比依旧极具性价比。
开源与生态建设
DeepSeek通过开源核心模型和硬件效率提升的相关方法论,推动了国产大模型生态的崛起。其开源周连续发布了多个高效工具,如FlashMLA、DeepEP等,为行业提供了宝贵的资源。
算力经济学
DeepSeek的成功摸索出了一套在“算力受限”条件下提升算力效率的路径,推动了“AI技术平权”和“AI普惠”。其爆火出圈为国产算力带来了5000亿的市场机会,激活了国产芯片及AI硬件的研发。
未来发展趋势
多模态能力与训练方法优化
DeepSeek未来将持续优化多模态能力和训练方法,推动AI模型在更多垂直领域的应用。
人机协作与AI Agent普及
随着AI技术的普及,AI Agent将深化人机协作,推动“超级个体”的诞生。
政策与伦理治理
AI决策的介入将引发权力失衡风险,数据垄断可能形成“模型封建制”。未来可能通过AI税调节技术红利分配,加大基础设施投入。
结论
DeepSeek-V3标志着AI进入“成本驱动普及、垂直应用爆发”的新阶段。其技术创新和行业影响不仅重塑了产业格局,更为AI技术的普惠和可持续发展提供了新的思路。未来,DeepSeek将继续引领AI领域的技术革新,推动人机共生与社会包容性发展。







