从统计到神经机器翻译:NLP的早期演进
自然语言处理(NLP)的早期发展主要依赖于统计和规则方法。20世纪90年代,基于统计的机器翻译(SMT)成为主流,通过分析大量双语语料库,模型能够预测源语言和目标语言之间的对应关系。然而,这种方法在处理复杂句法和语义时表现有限,尤其是在面对歧义和长距离依赖时。
进入21世纪,神经机器翻译(NMT)的出现标志着NLP的一次重大突破。NMT采用深度神经网络,尤其是序列到序列(Seq2Seq)模型,能够更好地捕捉语言中的上下文信息。2016年,谷歌推出的GNMT系统在多个翻译任务中取得了显著进展,展示了NMT的潜力。然而,NMT仍然面临数据依赖性强、训练成本高等问题。
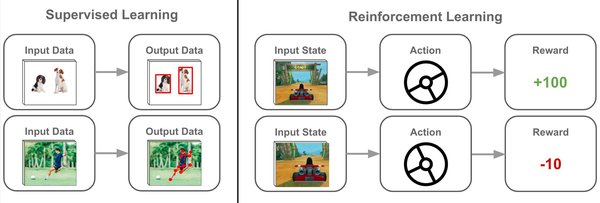
强化学习与大语言模型的崛起
近年来,基于强化学习的大语言模型(LLM)逐渐成为NLP领域的新焦点。强化学习通过奖励机制引导模型优化决策过程,使得模型能够在复杂任务中表现出更强的适应性和泛化能力。OpenAI的ChatGPT和DeepSeek的R1模型是这一领域的代表性成果。
ChatGPT通过大规模预训练和强化学习微调,展示了在对话生成、文本摘要等任务中的卓越表现。然而,ChatGPT的广泛应用也引发了关于其对社会影响的讨论,尤其是对英语教学和人工翻译行业的冲击。尽管ChatGPT能够快速生成高质量的翻译文本,但它在处理文化差异和人文语境时仍存在不足,无法完全替代人类翻译的创造力和情感理解。
中科院物理所的贝叶斯概率分析
中科院物理所从贝叶斯概率的角度对机器翻译的准确性进行了深入研究。研究表明,机器翻译的准确性不仅依赖于模型的架构和训练数据,还与语言的统计特性密切相关。贝叶斯方法通过引入先验概率和后验概率,能够更好地量化翻译中的不确定性,从而提高模型的鲁棒性。这一研究为NLP模型的优化提供了新的理论支持。
大模型在上下文理解中的进展与挑战
大语言模型在上下文理解方面取得了显著进展。例如,DeepSeek的R1模型通过引入思维链(Chain-of-Thought)和蒙特卡洛树搜索(MCTS)等技术,能够在复杂的数学和编码任务中展现出类似人类的推理能力。然而,尽管大模型在处理结构化任务时表现出色,它们在理解人文语境和文化背景方面仍存在局限。
例如,在文学翻译或诗歌创作中,大模型往往难以捕捉到语言的微妙情感和隐喻意义。这种局限性表明,NLP模型在处理非结构化、情感丰富的文本时,仍需进一步改进。
未来方向:多模态与跨语言理解
未来的NLP研究将更加注重多模态和跨语言理解。视觉-语言-动作模型(VLA)如ChatVLA通过融合视觉、语言和动作信息,展示了在机器人控制和多模态理解任务中的潜力。ChatVLA采用分阶段对齐训练和混合专家架构(MoE),显著提升了模型的参数效率和任务适应性。
此外,跨语言理解也是NLP的重要发展方向。通过引入多语言数据集和跨语言预训练技术,大模型能够更好地处理不同语言之间的翻译和交互任务。例如,DeepSeek的多语言模型在多个语言对中表现出色,展示了跨语言理解的潜力。
结论
从统计到强化学习,NLP在机器翻译和语言理解方面取得了显著进展。然而,大模型在处理人文语境和文化差异时仍面临挑战。未来的研究应更加注重多模态融合和跨语言理解,以实现更加智能和人性化的自然语言处理系统。
| 模型/技术 | 主要贡献 | 局限性 |
|---|---|---|
| 统计机器翻译 | 基于双语语料库的翻译 | 处理复杂句法和语义有限 |
| 神经机器翻译 | 上下文捕捉能力强 | 数据依赖性强,训练成本高 |
| 强化学习大模型 | 复杂任务适应性强 | 人文语境理解不足 |
| 贝叶斯概率分析 | 量化翻译不确定性 | 理论复杂,计算成本高 |
| 多模态模型 | 融合视觉、语言和动作信息 | 多模态数据获取困难 |
通过不断优化模型架构和训练策略,NLP有望在未来实现更加广泛和深入的应用,推动人工智能技术的进一步发展。






