在当今的机器学习领域,GPU编程已成为不可或缺的技能。CUDA和Triton作为两大主流框架,为开发者提供了强大的工具来加速计算。本文将为你提供一个30天的自学计划,帮助零基础学习者快速掌握这些技术,并将其应用于实际项目中。
第一阶段:基础知识与早期实践(第1-7天)
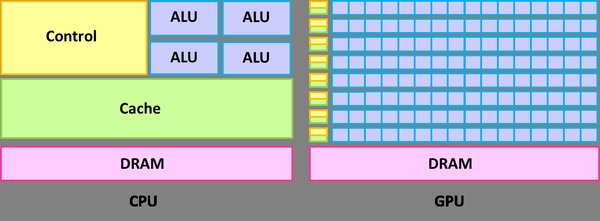
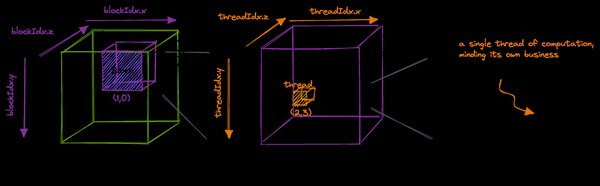
- 第1-2天:了解GPU架构与CUDA基础概念,包括线程、块、网格等。
- 第3-4天:安装CUDA工具包,编写并运行第一个CUDA程序。
- 第5-7天:深入学习CUDA内存模型,实践共享内存和全局内存的使用。
第二阶段:深入CUDA编程(第8-14天)
- 第8-10天:掌握CUDA流与事件,优化数据传输与并发执行。
- 第11-12天:学习CUDA库,如cuBLAS和cuFFT,进行矩阵运算和快速傅里叶变换。
- 第13-14天:实践CUDA调试与性能分析工具,如Nsight和nvprof。
第三阶段:Triton入门与集成(第15-21天)
- 第15-17天:了解Triton框架,学习其基本语法与操作。
- 第18-19天:将Triton与PyTorch集成,实现自定义核函数。
- 第20-21天:实践Triton的高级特性,如自动微分与并行计算。
第四阶段:项目实践与应用(第22-30天)
- 第22-24天:选择一个机器学习项目,如图像分类或自然语言处理,应用CUDA和Triton进行加速。
- 第25-27天:优化项目性能,实践多GPU并行计算。
- 第28-30天:总结学习成果,撰写项目报告,分享经验与心得。
计划亮点:
- 早期实践:从第一天开始编写代码,快速上手。
- 全面覆盖:涵盖CUDA和Triton的核心知识点。
- PyTorch集成:与流行的机器学习框架无缝对接。
- 项目驱动:通过实际项目巩固所学知识。
通过这个30天的自学计划,你将能够从零基础迅速成长为GPU编程的高手,并将这些技能应用于机器学习领域。立即开始你的学习之旅,开启高效计算的新篇章!
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...









AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。