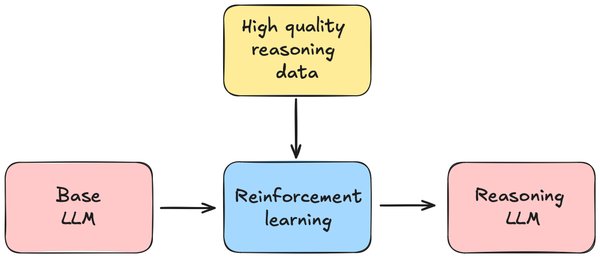
DeepSeek模型的核心理念
DeepSeek模型是近年来AI领域的一项重大突破,其核心在于通过创新的强化学技术(Reinforcement Learning, RL)和优化算法,以更低的算力成本实现与当前最强大模型相当的能力。与传统的监督微调(Supervised Fine-Tuning, SFT)不同,DeepSeek直接应用强化学,使模型能够通过自我验证和反思生成长链思维(Chain-of-Thought, CoT),从而解决复杂问题。
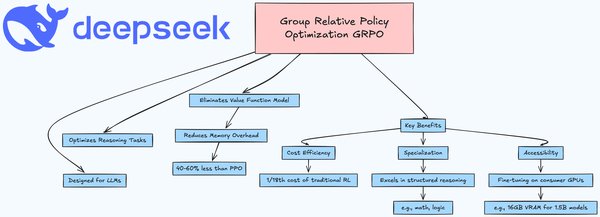
GRPO算法:强化学的革新
DeepSeek的核心技术之一是Group Relative Policy Optimization(GRPO)算法。这一算法通过以下步骤实现高效训练:
1. 多解答生成:模型针对同一问题生成多个解答,类似于学生尝试不同解题方法。
2. 相对评价:在生成的解答中进行相对评价,而非依赖绝对评分。
3. 优化与调整:根据评价结果,强化优质解答模式,减少错误解答。
GRPO的优势在于其灵活性和效率:
– 无需专用报模型:任何函数或模型均可用于评价。
– 稳定性与效率:通过组内比较,实现更稳定的学习过程。

算力优化:低资源高回报
DeepSeek团队在算力优化方面也取得了显著成果。他们采用了以下技术:
– 混合精度计算:使用8位浮点数(5E2M)和自定义12位浮点数(E5M6)进行前向传递,大幅降低计算资源需求。
– 通信优化:通过重叠计算与通信、动态负载均衡等技术,减少GPU间的通信延迟。
– 内存管理:优化器状态使用16位(BF16),进一步节省内存。
开源与免费:AI社区的未来
与OpenAI的闭源和收费模式不同,DeepSeek坚持开源和免费,为全球开发者提供了学习和创新的平台。Hugging Face作为开源社区的代表,也积极参与DeepSeek的推广,提供了详细的课程和资源,帮助开发者深入理解其技术细节。
挑战与展望
尽管DeepSeek取得了显著进展,但仍面临一些挑战:
1. 计算成本:GRPO的多解答生成机制增加了计算负担。
2. 报函数设计:报函数的设计对学习效果有重要影响,需谨慎优化。
3. 动态调整:KL散度惩罚和组大小等参数需要动态调整,以平衡学习稳定性与多样性。
未来,DeepSeek有望在更大规模模型和更复杂任务中实现进一步突破,为AI领域带来更多创新。
结语
DeepSeek模型通过GRPO算法和强化学技术,实现了高效训练与算力优化的完美结合。其开源和免费模式不仅推动了AI技术的发展,也为全球开发者提供了宝贵的资源。在未来的AI竞赛中,DeepSeek无疑将成为一股不可忽视的力量。





