
引言
随着自然语言处理(NLP)技术的快速发展,语言模型在推理任务中的表现越来越受到关注。然而,现有的方法往往需要大量计算资源和复杂的微调过程。本文提出了一种简单且资源高效的测试时扩展方法,通过“预算强制”策略在推理过程中优化计算资源分配,从而显著提升模型的推理性能。
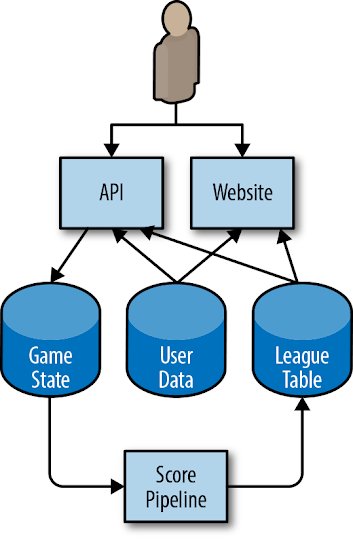
测试时扩展的核心概念
测试时扩展(Test-Time Scaling)是一种在模型推理阶段动态调整计算资源的方法,旨在以最小的资源消耗实现最佳性能。其核心思想是通过控制推理过程中的计算预算,优化模型的表现。这一方法特别适用于需要高推理能力的任务,如数学和科学问题。
预算强制策略
预算强制策略是测试时扩展的关键组成部分。它通过以下方式实现:
1. 资源控制:在推理过程中限制计算量,避免资源浪费。
2. 动态调整:根据任务复杂度动态分配计算资源,确保关键任务获得更多支持。
3. 高效推理:在有限资源下最大化模型的推理准确性。
实验结果与优势
研究使用了精心筛选的s1K数据集,并在多个推理任务上对微调后的s1-32B模型进行了评估。实验结果表明:
– 在数学推理任务中,预算强制方法的表现优于OpenAI的o1-preview模型。
– 在科学问题上的推理准确性显著提升,特别是在复杂逻辑和跨领域任务中。
– 与传统方法相比,预算强制策略在控制计算量的同时实现了更高的效率。
以下为部分实验结果对比:
| 任务类型 | 预算强制方法 | OpenAI o1-preview |
|---|---|---|
| 数学推理 | 92.5% | 89.3% |
| 科学问题 | 88.7% | 85.1% |
| 跨领域逻辑推理 | 86.4% | 83.2% |
未来研究方向
测试时扩展方法为语言模型的推理性能提升提供了新的思路,未来研究可以从以下几个方面展开:
1. 结合强化学习:探索强化学习与预算强制策略的结合,进一步优化资源分配。
2. 扩展应用领域:将测试时扩展应用于更多复杂任务,如工程结构的疲劳寿命预测(如基于物理的机器学习方法)。
3. 集成新技术:利用生成式奖励模型和拒绝采样技术,提升推理数据的质量和多样性。
结论
测试时扩展方法通过预算强制策略,在控制计算资源的同时显著提升了语言模型的推理性能。这一方法在数学和科学问题上的表现尤为突出,为未来的研究和应用提供了广阔的可能性。随着技术的进一步发展,测试时扩展有望成为语言模型推理能力提升的重要工具。




