DeepSeek,一家专注于大语言模型开发的创新型科技公司,在2024年底发布了新一代大语言模型V3,并在2025年世界经济论坛上推出了开源模型R1。这一系列技术突破不仅颠覆了AI行业的传统认知,也为未来的AI发展指明了方向。
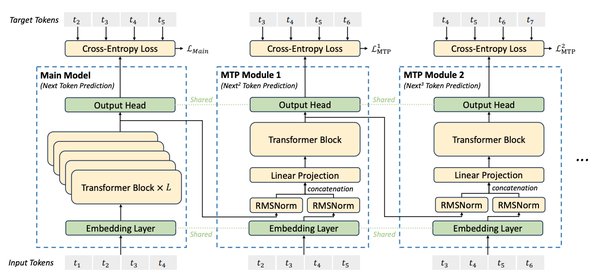
DeepSeek V3的技术突破
低成本训练:重新定义AI开发
DeepSeek V3的最大亮点之一是其极低的训练成本。根据技术报告,V3的训练成本仅为557.6万美元,远低于OpenAI GPT-4o的1亿美元。这一成就得益于以下技术创新:
– 混合精度计算:使用8位浮点数(FP8)和12位浮点数(E5M6)进行前向计算,大幅降低了计算资源需求。
– GPU优化:通过深度编程(如PTX语言)和GPU架构的充分利用,将冗余计算减少了80%。
– 通信优化:通过重叠计算与通信,并动态调整专家模型分配,进一步提升了训练效率。
MoE架构:高效与性能的平衡
DeepSeek V3采用了Mixture of Experts(MoE)架构,通过256个专家模型的协作,显著降低了计算成本并提升了性能。具体特点包括:
– 专家粒度细化:每个MoE层包含256个专家模型,每个token仅激活8个专家模型,减少了计算负担。
– 共享专家机制:引入共享专家模型,进一步优化了资源利用率。
– 均衡化技术:通过动态负载均衡和辅助损失函数,避免了资源分配不均的问题。
DeepSeek的开源策略与行业影响
开源化浪潮:推动AI普及
DeepSeek V3和R1的开源策略,不仅降低了AI技术的使用门槛,还加速了AI在企业和个人中的普及。其优势体现在:
– 本地化部署:用户可以在高性能PC上运行DeepSeek模型,无需依赖云端服务器,保障了数据安全。
– 技术透明性:通过公开技术报告和源代码,DeepSeek推动了行业技术的共享与创新。
– 生态竞争:开源策略迫使其他AI企业(如Meta和阿里巴巴)加速开放技术,推动了整个行业的进步。
对AI行业的影响
DeepSeek的低成本和高性能模型,直接挑战了传统的“规模法则”(Scale Law),即通过扩大模型规模实现性能提升。这一突破引发了以下行业变革:
– 投资风向转变:AI基盘企业(如NVIDIA)的股价因需求预期下降而大幅波动。
– 技术范式转移:更多企业开始关注模型优化和开源技术,而非单纯追求规模。
– 社会应用扩展:轻量级AI模型的普及,使得AI在移动设备和边缘计算中的应用成为可能。

未来展望:AI技术的下一站
DeepSeek的成功不仅是一次技术突破,更是AI行业发展的里程碑。未来,我们有望看到以下趋势:
– 模型轻量化:通过蒸留、量化和压缩技术,进一步降低模型运行门槛。
– 多模态融合:结合图像、语音和文本处理能力,构建更全面的AI系统。
– 社会实装加速:AI技术将在医疗、教育、金融等领域实现大规模应用,推动社会生产力的提升。
DeepSeek V3的出现,标志着AI技术进入了一个新时代。它不仅重新定义了AI开发的边界,也为全球AI行业注入了新的活力。未来,随着技术的不断演进,AI将更深入地融入我们的生活,成为推动社会进步的重要力量。







