引言
随着人工智能技术的飞速发展,视觉-语言-动作(VLA)大模型逐渐成为具身智能领域的核心驱动力。VLA模型不仅能够感知和理解环境,还能通过自然语言指令生成相应的动作,实现与物理世界的交互。本文将深入探讨VLA大模型的技术突破、应用场景以及未来挑战。
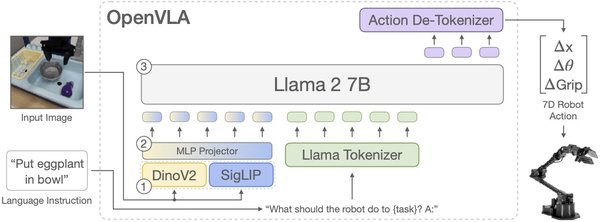
VLA大模型的技术突破
Figure AI的Helix模型
Figure AI推出的Helix模型是首个能够输出高频率连续控制整个仿人上半身的VLA模型。Helix通过自然语言提示拾取绝大多数家用品,无需事前代码或培训。其内置的双系统协同运行,兼顾了速度与泛化能力。Helix的训练过程是完全端到端的,通过标准回归损失将原始像素和文本命令映射到连续动作,并引入了时间偏移来模拟实际部署中的推理延迟,确保模型在真实场景中的稳定性。
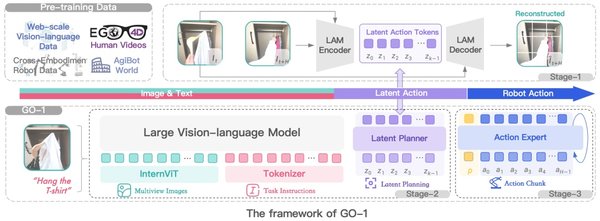
智元的GO-1模型
智元启元大模型GO-1开创性地提出了Vision-Language-Latent-Action (ViLLA)架构。GO-1通过预测隐式动作标记,弥合了图像-文本输入与机器人执行动作之间的鸿沟。GO-1在真实世界的灵巧操作和长时任务方面表现卓越,平均成功率提高了32%。其小样本快速泛化能力和持续进化特性,使得GO-1能够快速适应新任务和新场景。
Magma模型
Magma模型通过标记集合(SoM)和标记轨迹(ToM)技术,将视觉语言数据转化为可操作任务,显著提升了空间智能和任务泛化能力。Magma在UI导航和机器人操作任务上实现了最佳性能记录,同时在图像和视频相关多模态任务中的表现也优于其他常用的多模态模型。
VLA大模型的应用场景
机器人操作
VLA大模型在机器人操作领域的应用尤为广泛。Helix和GO-1模型在真实世界的灵巧操作和长时任务方面表现卓越,能够通过自然语言指令实现复杂的操作任务。Magma模型在机器人操作任务上的表现也优于其他模型,展现了其在空间推理能力上的优势。
多模态理解
VLA大模型在多模态理解任务中表现出色。Magma模型在视觉问答(VQA)和图像推理基准测试上表现优异,尤其是在TextVQA和ChartQA任务上,分别取得了约5%和22%的显著提升。GO-1模型通过结合互联网视频和真实人类示范进行学习,增强了对人类行为的理解。
VLA大模型的未来挑战
数据稀缺
现有的视觉语言动作数据在数量和多样性上都较为有限,没有足够的数据用于扩大模型规模。如何构建一个统一的预训练接口,实现联合训练,是VLA大模型面临的主要挑战之一。
泛化能力
尽管VLA大模型在特定任务上表现出色,但在跨任务和跨领域的泛化能力上仍存在不足。如何提升模型的泛化能力,使其能够适应更多样化的场景和任务,是未来研究的重要方向。
计算资源
VLA大模型的训练和推理需要大量的计算资源。如何优化模型的计算效率,降低对硬件资源的需求,是VLA大模型在实际应用中需要解决的问题。
结论
VLA大模型在具身智能领域的应用前景广阔,Helix、GO-1和Magma模型的技术突破为机器人操作和多模态理解带来了新的可能性。然而,数据稀缺、泛化能力和计算资源等挑战仍需进一步研究和解决。随着技术的不断进步,VLA大模型有望在更多领域发挥重要作用,推动具身智能向通用化、开放化、智能化方向迈进。
参考文献
- 新智元:Magma模型的技术细节与应用
- 智元机器人:GO-1模型的技术架构与实验效果
- Figure AI:Helix模型的技术突破与未来展望







