
生成式大模型幻觉检测的挑战
生成式大模型(如GPT、LLaVA等)在自然语言处理和多模态任务中展现出强大的能力,但其生成内容中常伴随“幻觉”问题,即模型生成与事实不符或缺乏依据的信息。这种现象在通用场景下可能影响有限,但在法律、医学等对准确性要求极高的领域,幻觉问题将带来潜在风险。
幻觉的成因
-
模型容量的限制:小规模模型在处理复杂任务时,难以生成准确答案,甚至可能重复错误。
-
奖励信号质量的局限性:现有奖励模型在有限多样性的数据集上训练,难以提供有效的奖励信号。
-
动态知识更新的不足:企业内部知识动态变化,模型未能及时学习和适应,导致输出结果滞后。
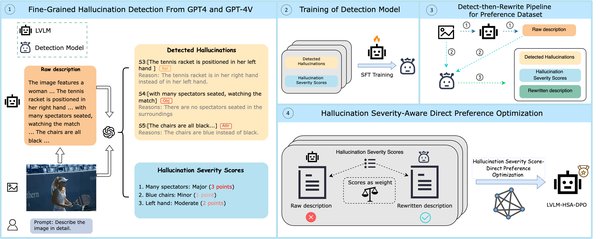
多模态对齐与幻觉检测的突破
为了应对幻觉问题,快手、中科院、南大合作提出了一套多模态对齐(MM-RLHF)方案,通过数据集、奖励模型和训练算法的创新,显著提升了模型的安全性与准确性。
核心创新
-
高质量数据集:引入包含120k精细标注的偏好比较对数据集,涵盖有用性、真实性和伦理性三个维度,由50名标注人员和8名专家耗时两个月完成。
-
基于批评的奖励模型:提出Critique-Based Reward Model,首先生成批评,再基于批评打分,提供更好的可解释性和反馈。
-
动态奖励缩放:根据奖励差距动态调整样本的损失权重,优先利用高置信度的样本对,提高数据使用效率。
显著成果
-
对LLaVA-ov-7B模型进行微调后,会话能力平均提升19.5%,安全性平均提升60%。
-
在10个评估维度和27个基准上均取得一致性能增益,尤其在多模态安全性基准(MM-RLHF-SafeBench)中表现突出。
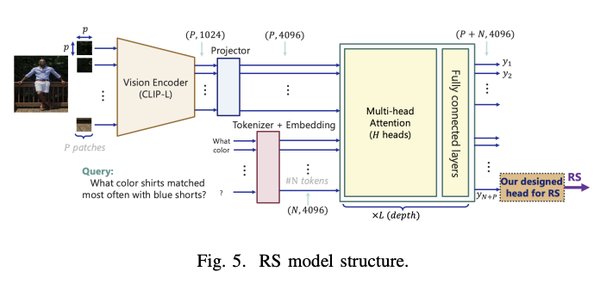
未来研究方向
尽管多模态对齐技术已取得显著进展,但幻觉检测仍面临诸多挑战。未来研究可关注以下方向:
-
充分利用数据集注释粒度:挖掘数据集中的分数和排名理由,结合先进优化技术提升模型性能。
-
高分辨率数据的应用:解决特定基准的局限性,进一步提升模型在复杂任务中的表现。
-
半自动化策略的扩展:高效扩展数据集,覆盖更多领域和场景,增强模型的泛化能力。
企业落地中的幻觉检测实践
在企业应用中,大模型幻觉问题尤为突出。浪潮信息的元脑企智 EPAI 平台与 DeepSeek 大模型深度结合,通过模型微调、知识检索和智能体编排等技术,显著降低了幻觉发生率。
核心工具
-
知识检索模块:采用端到端优化的 RAG pipeline 架构,提升检索精度。
-
插件管理模块:实时接入企业知识库,确保信息获取的准确性和时效性。
-
智能体编排模块:建立多模型协同工作机制,降低单一模型偏差风险。
实测效果
-
DeepSeek 在元脑企智 EPAI 上开发的企业应用回答准确率达到95%。
-
某制造企业使用该平台开发质检智能体应用,需求响应周期从3周缩短至3天,开发效率提升5倍以上。
结语
生成式大模型幻觉检测是人工智能安全领域的重要课题。通过多模态对齐、动态奖励缩放和企业级落地实践,我们正在逐步解决这一难题,为大模型的安全性与准确性保驾护航。未来,随着技术的不断进步,幻觉检测将成为推动人工智能安全发展的重要基石。









