
引言
随着AI技术的飞速发展,大模型(如GPT、LLaVA等)的应用逐渐从云端走向终端设备。然而,终端设备的算力有限,如何在这些设备上实现流畅的AI应用成为了行业关注的焦点。本文将通过分析ICML和CVPR等顶级会议的最新研究成果,以及高通公司在AI研发方面的长期努力,探讨这一问题的解决方案。

大模型在终端设备的挑战
在算力有限的终端设备上部署大模型,主要面临以下几个挑战:
-
计算性能:大模型通常需要大量的计算资源,而终端设备的处理器和内存有限。
-
内存效率:大模型的内存占用较高,如何在有限的内存中高效运行是关键。
-
功耗控制:终端设备对功耗要求严格,如何在保证性能的同时降低功耗是难题。
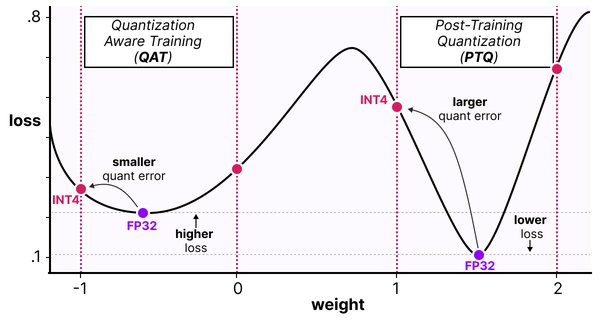
量化技术的应用
量化技术是解决上述挑战的有效方法之一。通过将模型的权重从高精度浮点数转换为低精度整数,可以大幅提高计算性能和内存效率。高通公司的研究表明,生成式AI模型可以量化至INT4模型,在不影响准确性和性能表现的情况下,能节省更多功耗,与INT8相比实现90%的性能提升和60%的能效提升。
硬件加速的支持
终端侧的AI加速离不开硬件的支持。高通AI引擎采用异构计算架构,包括Hexagon NPU、高通Adreno GPU、高通Kryo CPU或高通Oryon CPU。其中,Hexagon NPU在性能表现上,比前代产品快98%,同时功耗降低了40%。架构方面,Hexagon NPU升级了全新的微架构,全面提升了生成式AI的响应能力,使得手机上的大模型“秒答”用户提问成为可能。
全栈AI优化
高通公司不仅在理论研究方面快马加鞭,还通过全栈AI研究和优化,加速AI应用在实践中的部署。高通AI软件栈是一套容纳了大量AI技术的工具包,全面支持各种主流AI框架、不同操作系统和各类编程语言,能提升各种AI软件在智能终端上的兼容性。基于高通AI软件栈,只需一次开发,开发者就能跨不同设备随时随地部署相应的AI模型。
结论
在大模型时代,AI应用的普及化不仅依赖于基础模型的创新,更依赖于从模型量化压缩到部署的全栈AI优化。高通公司在AI研发方面的长期努力,特别是在终端设备上实现感知、推理和行为等核心能力,为AI应用的普及化奠定了坚实的基础。未来,随着技术的不断进步,AI应用将在更多终端设备上实现“触手可及”的体验。
参考文献
-
ICML 2024, CVPR 2024
-
高通公司《让AI触手可及》白皮书








