OpenAI推出的AI视频生成模型Sora,凭借其高清晰度、连贯性和时间一致性,迅速成为业界关注的焦点。Sora的核心技术之一——Spacetime Patch,基于谷歌DeepMind的早期研究,为视频生成领域带来了革命性的突破。本文将深入探讨Spacetime Patch的原理及其在Sora中的应用,分析其在视频生成领域的创新与挑战。

Spacetime Patch:视频生成的基础单元
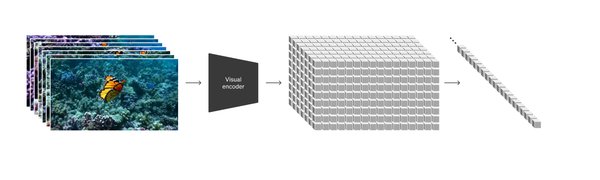
Spacetime Patch是Sora模型的核心技术之一,它将视频分解为一系列空间-时间块(spatiotemporal patches)。这种处理方式不仅保持了视频的原始宽高比和分辨率,还确保了帧与帧之间的自然运动。通过将视频视为一个空间和时间的序列,Spacetime Patch能够更高效地捕捉视频中的动态信息,从而实现更逼真的视频生成。
具体来说,Spacetime Patch技术通过以下方式优化视频生成:
-
高效信息表示:将视频分解为小块,便于模型处理复杂的时空信息。
-
自然运动生成:通过处理空间和时间的连续块,确保视频中的运动流畅且符合物理规律。
-
灵活性与可扩展性:支持不同分辨率和时长的视频生成,为未来的技术迭代奠定基础。

Spacetime Patch与Diffusion Transformer的结合
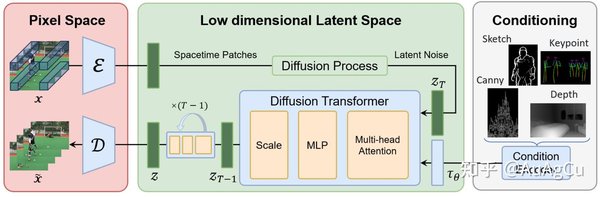
Sora的另一项核心技术是Diffusion Transformer(DiT)架构。尽管DiT论文曾因“缺少创新性”被拒绝,但它现已成为Sora的核心理论之一。DiT通过自注意力机制(self-attention)和扩散模型(diffusion model)的结合,进一步增强了Spacetime Patch的效能。
具体而言,DiT架构在以下方面对Spacetime Patch进行了优化:
-
帧间一致性:通过自注意力机制,确保视频帧之间的连贯性。
-
文本条件生成:结合自然语言输入,实现基于文本提示的视频生成。
-
风格控制:通过强化学习技术,适应不同的艺术风格和电影技巧。
Spacetime Patch的挑战与未来
尽管Spacetime Patch在视频生成中表现出色,但仍面临一些挑战。例如,模型在处理复杂的物理交互(如液体、布料和阴影的运动)时仍存在不一致性。此外,逻辑事件序列的维护和文本模糊性处理也是当前的技术瓶颈。
然而,随着技术的不断进步,Spacetime Patch和DiT架构的结合有望在以下方面取得突破:
-
更高分辨率输出:支持4K甚至8K视频的生成。
-
实时生成能力:减少生成时间,提升用户体验。
-
改进物理模拟:增强视频中物体运动的真实感。
结语
Spacetime Patch作为Sora模型的核心技术,为AI视频生成领域带来了新的可能性。它不仅提升了视频的清晰度和连贯性,还为未来的技术发展奠定了基础。尽管仍面临一些挑战,但随着研究的深入,Spacetime Patch有望在更多应用场景中发挥其潜力,推动数字内容创作的进一步革新。





