Transformer技术:SOTA翻译的核心驱动力
Transformer模型自2017年提出以来,已成为自然语言处理(NLP)领域的基石。其在SOTA(State of the Art)翻译中的应用,展现了高准确性、流畅性和实时性的显著优势。Transformer的核心机制——自注意力(Self-Attention)和多头注意力(Multi-Head Attention),能够捕捉文本中的长距离依赖关系,从而实现更精准的语义理解。
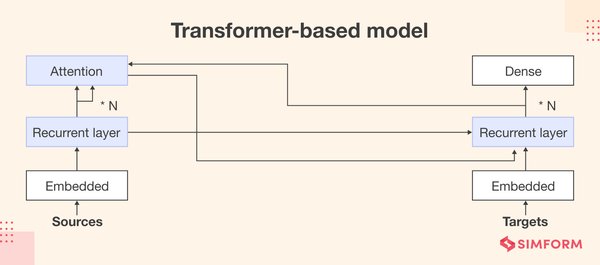
在翻译任务中,Transformer通过编码器-解码器架构,将源语言文本编码为潜在表示,再通过解码器生成目标语言文本。其独特的残差连接(Residual Connection)和层归一化(Layer Normalization)机制,进一步提升了模型的稳定性和训练效率。
从翻译到生成AI:Transformer的跨领域创新
Transformer的应用已从翻译扩展到生成AI领域。例如,株式会社ユニリタ推出的「Waha! Transformer」工具,通过生成AI连携功能,实现了数据自动化处理和高效学习。该工具无需编程知识,即可完成复杂的数据整合与生成AI的协同工作,展现了Transformer在商业应用中的潜力。
此外,最新的生成AI模型如Qwen2.5-VL和Zamba2,进一步优化了Transformer架构。Qwen2.5-VL通过窗口注意力(Window Attention)和动态分辨率扩展,提升了视频理解能力;而Zamba2结合状态空间模型(State-Space Models)与Transformer,实现了更高效的文本生成。

Transformer技术的前沿发展与挑战
Transformer技术在不断演进中,也面临着一些挑战。例如,模型的计算复杂度和内存消耗限制了其在边缘设备上的应用。然而,轻量级模型如Helium-1的出现,为Transformer在移动设备上的部署提供了新思路。
同时,Transformer在视觉任务中的应用也取得了显著进展。如DepthPro模型通过多尺度视觉Transformer(ViT)架构,实现了高分辨率深度图的生成;而RT-DETRv2则通过选择性多尺度特征提取,提升了实时目标检测的性能。
结语:Transformer的未来展望
Transformer技术以其强大的语义理解能力和跨领域适应性,正在重塑翻译、生成AI和视觉处理等多个领域。随着模型的不断优化和创新,Transformer将在更多场景中展现其价值,推动人工智能技术的边界不断扩展。
无论是SOTA翻译的高精度实现,还是生成AI的广泛应用,Transformer都将继续引领技术革新,为跨语言沟通和智能决策提供强有力的支持。









