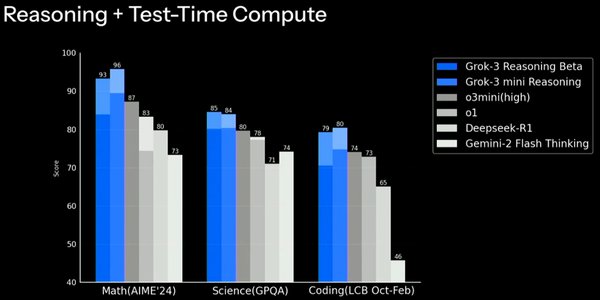
Grok 3与o3-mini-high的基准测试争议
近期,马斯克旗下的人工智能公司xAI发布了Grok 3大模型,宣称其为“地球上最聪明的AI”。然而,这一宣称在基准测试中引发了与OpenAI的o3-mini-high的激烈争议。xAI发布的图表显示,Grok 3在AIME 2025数学测试中表现优异,超越了o3-mini-high。但OpenAI员工指出,xAI的图表未包含o3-mini-high在“cons@64”条件下的得分,这是一种允许模型多次尝试并选取最优答案的测试方法。若开启此功能,o3-mini-high的得分将大幅提升,与Grok 3的差距几乎消失。

算力堆积与技术优化的分野
Grok 3的“20万张GPU训练”豪言,展现了其强大的算力支持。然而,这种算力堆积是否真正推动了技术进步,还是仅仅制造了数据幻觉,引发了业界质疑。在实际测试中,Grok 3在速度上表现惊艳,但在逻辑推理和语义理解上却频频出错。例如,面对“老鹰为何能飞?”的问题,Grok 3给出了“因为老鹰需要吃蛇维持体力”的荒谬回答,而国产模型DeepSeek R1则精准指出“老鹰属于鸟类,具备飞行生理结构”。
相比之下,DeepSeek R1采用了动态逻辑链分解技术,将复杂问题拆解为可验证的子步骤,不仅训练成本仅为Grok 3的1%,在多项测试中表现也优于Grok 3。这证明,技术优化比算力堆砌更具价值。
AI评测标准的信任危机
这场争议暴露了AI评测标准的深层次问题。企业通过选择性披露数据、模糊对比条件,将评测结果包装为“技术突破”。例如,Meta仅展示Llama 2在自研安全测试集中的成绩,却隐瞒其在视频理解任务中的性能滑坡;Anthropic将模型“拒绝作恶”的比例从62%包装为“超80%”。这种“自定义游戏”不仅误导了公众,也将企业逼入“数据造假”的恶性循环。
开源与闭源的技术路线之争
Grok 3的“延迟开源”策略,试图平衡商业化与开源需求。然而,其高昂的训练成本和闭源模式,与DeepSeek的开源免费形成了鲜明对比。DeepSeek通过开源代码库,将技术研究免费赋能给全球开发者,推动了AI行业的集体进步。这种低成本、高效率的技术路径,正在重新定义AI发展的未来。
结语
Grok 3与o3-mini-high的争议,不仅是技术实力的较量,更是算力堆积与技术优化的路线之争。当AI评测标准沦为企业的“自定义游戏”时,如何确保公正性和透明度,成为行业亟待解决的问题。未来,AI的发展不仅需要强大的算力支持,更需要回归技术本源,让每一次进步都经得起最苛刻的审视。





