在人工智能领域,模型训练的效率与成本一直是制约技术发展的关键因素。DeepSeek通过其创新的混合专家架构(MoE),不仅实现了高性能AI模型的训练,还大幅降低了成本,为行业带来了革命性的突破。


MoE架构:专家协作的效率引擎
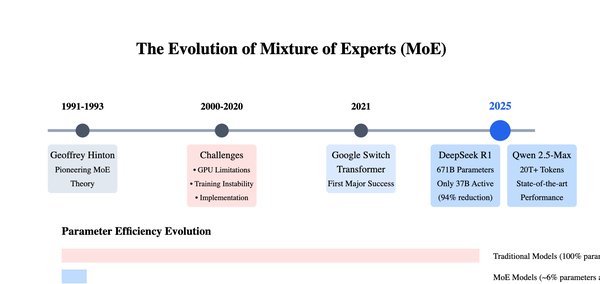
MoE架构的核心思想是将复杂任务分解为多个子任务,由不同的专家网络分别处理。这种“按需激活”的策略显著减少了不必要的计算量。以DeepSeek-V3为例,其总参数高达6710亿,但每个输入仅激活370亿参数,这种智能资源管理方式让模型在处理复杂任务时更加高效。
DeepSeek在MoE架构上的创新包括:
-
精细化专家分割:将专家细分为多个单元,灵活激活响应单元,实现知识的细粒度分解。
-
共享专家隔离:保留部分专家作为共享专家,专注于通用知识,减少非共享专家之间的冗余。
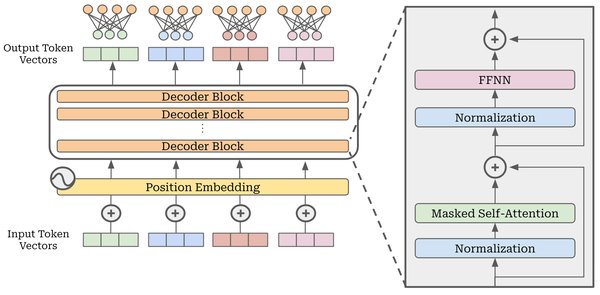
DeepEP:高效通信的解决方案
在MoE架构中,专家并行策略(EP)面临高通信成本的挑战。DeepSeek开源的DeepEP通信库通过以下特性解决了这一问题:
-
高效的全对全通信:支持NVLink和RDMA,优化了节点内和跨节点的数据传输。
-
低精度运算支持:原生支持FP8,显著降低内存占用和计算成本。
-
灵活的资源调度:通过SM数量控制和通信-计算重叠技术,最大化硬件利用率。
DeepEP的推出不仅提升了MoE模型的训练效率,还为AI基础设施的可能性拓宽了边界。

FP8混合精度训练:成本与效果的平衡术
传统训练方法通常采用FP32等高精度数据类型,计算量大且成本高昂。DeepSeek的FP8混合精度训练在保证模型准确性的同时,大幅降低了训练成本。其创新包括:
-
细粒度量化:将数据分解为更小的组,精细平衡准确度与效率。
-
混合精度策略:在关键模块保留高精度数据格式,确保数值稳定性。
这种训练方式使得DeepSeek-V3的整体训练成本仅为557.6万美元,远低于GPT-4的7800万美元。
开源技术:推动AI平权化
DeepSeek在开源周中相继发布了FlashMLA和DeepEP等技术,不仅展示了其技术实力,还为全球开发者提供了高效工具。这些技术的开源标志着AI领域的平权化趋势,让更多团队能够以更低成本实现高性能模型训练。
未来展望:MoE架构的潜力
随着MoE架构的普及,未来芯片设计可能会针对不同MLP层进行定制化优化,进一步提升专家运算效率。同时,低精度训练和分布式并行策略的持续创新,将为AI模型训练带来更多可能性。
DeepSeek通过其在MoE架构上的创新,不仅推动了AI技术的发展,还为行业树立了高效、低成本训练的标杆。其开源技术的广泛应用,将进一步加速全球AI生态系统的繁荣。








