在当今AI大模型爆火的时代,如何低成本打造高质量私有模型,提升业务竞争力,成为众多企业和开发者关注的焦点。Colossal-AI发布的开源大模型后训练工具箱,为这一需求提供了强有力的支持。
Colossal-AI:开源大模型后训练工具箱
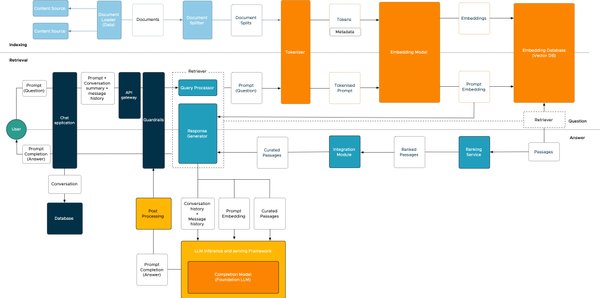
Colossal-AI的开源大模型后训练工具箱,包含多种微调和强化学习工具链,支持多种硬件和训练加速技术,提供灵活的并行策略配置接口。其主要特点包括:
-
DeepSeek V3/R1满血671B LoRA低成本SFT微调:通过LoRA优化,硬件资源消耗降低近10倍,最低硬件要求大幅降低。
-
完整的强化学习工具链:包括PPO、GRPO、DPO、SimPO等,支持灵活配置奖励函数、损失函数等。
-
多种硬件支持:兼容英伟达GPU、华为昇腾NPU等,支持混合精度训练、gradient checkpoint等训练加速技术。
-
灵活的并行策略配置:包括数据并行、模型并行、专家并行、ZeRO和Offload等,适应不同硬件规模。

DeepSeek-V3/R1:低成本微调的高质量私有模型
DeepSeek-V3/R1满血版参数高达6710亿,如何低成本进行微调呢?Colossal-AI提供了一键启动脚本,支持快速完成微调。其主要步骤包括:
-
数据集准备:接收JSONL格式的文件作为输入数据集,兼容Huggingface chat template,支持自定义system prompt。
-
模型权重准备:使用BF16权重进行微调,支持FP8权重转换为BF16。
-
使用方法:在准备好数据集和模型权重后,使用Colossal-AI提供的一键启动脚本,通过tensorboard记录学习率、loss、grad norm信息,方便对训练进行监控。
强化学习微调蒸馏版DeepSeek
Colossal-AI团队验证并实现了DeepSeek论文中的GRPO算法及verifiable reward,使用Qwen2.5-3B-Base模型进行了实验。其主要特点包括:
-
奖励设计:奖励=0,如果格式是错误的;奖励=1,如果格式是正确的但是结果是错误的;奖励=10,如果格式与结果都是正确的。
-
自我纠正:随着训练迭代,模型开始了自我纠正,平均奖励与模型回复长度逐步增长。
结论
Colossal-AI的开源大模型后训练工具箱,结合DeepSeek-V3/R1的低成本微调,为开发者提供了低成本打造高质量私有模型的解决方案。通过灵活的微调和强化学习工具链,支持多种硬件和训练加速技术,开发者可以快速构建适合自身业务需求的高质量私有模型,提升业务竞争力。






