OpenAI的首席技术官Murati近日宣布,GPT-5将在18个月后发布,并预计达到博士水平。这一消息引发了广泛关注,尤其是在AI领域的研究者和开发者中。与此同时,Claude 3.5 Sonnet在多个基准测试中刷新了SOTA(State of the Art),包括研究生级推理(GPQA)、本科级知识(MMLU)和编码能力(HumanEval),首次突破了GPQA 65%的分数,达到了最聪明的人类博士水平。
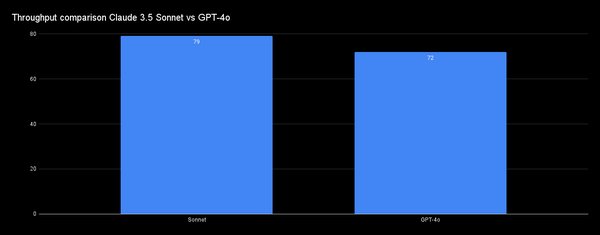
Claude 3.5 Sonnet在HumanEval上的表现
HumanEval是一个广泛使用的编码能力评估基准,用于测试AI模型在生成代码时的准确性和效率。Claude 3.5 Sonnet在这一测试中表现出色,展示了其在编码能力上的显著提升。与之前的模型相比,Claude 3.5 Sonnet不仅在代码生成的速度上有所提高,还在代码的正确性和逻辑性上取得了突破。
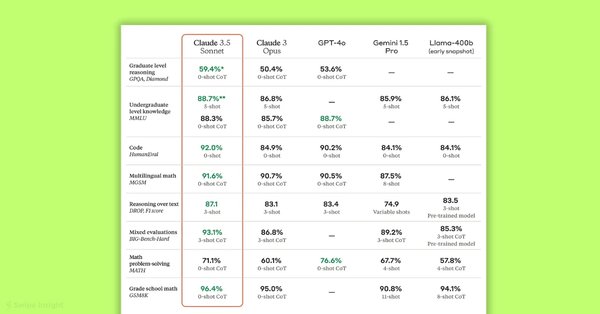
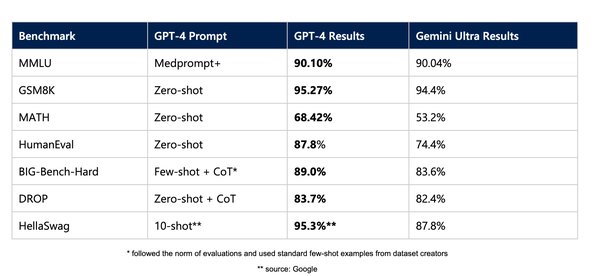
多语言代码生成与问题解决能力
为了更好地评估AI模型在代码生成中的表现,研究人员构建了一个多语言代码生成基准——PseudoEval。这一基准不仅包含问题-解决方案对,还提供了中间解决方案的伪代码表示,从而将问题解决能力与语言编码能力分离开来。通过这一方法,研究人员发现,尽管现有的大型语言模型(LLMs)在某些编程语言(如Python、C++和Rust)中能够成功生成代码,但在没有提供解决方案的情况下,所有实验模型都未能解决简单标记的问题。这表明,这些模型在问题解决能力上仍然存在瓶颈。

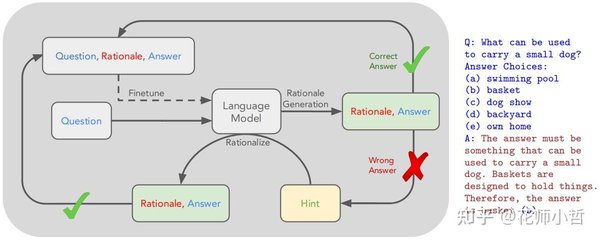
LLM生成代码的常见问题
尽管LLM在代码生成方面取得了显著进展,但它们生成的代码仍然存在一些常见问题。例如,LLM生成的深度学习代码中经常出现数据结构问题,如张量不匹配和维度错误。此外,逻辑错误和API误用也是LLM生成代码中的常见问题。这些问题与人类编写的代码中的错误模式相似,表明LLM在生成代码时仍然依赖于人类生成的训练数据,从而导致了这些共享的错误模式。
结论
GPT-5和Claude 3.5 Sonnet的发布标志着AI在推理和编码能力上的新突破。尽管这些模型在多个基准测试中表现出色,但在问题解决能力和代码生成的准确性上仍然存在挑战。未来的研究需要进一步探索如何提高LLM在代码生成中的问题解决能力,并减少常见的错误模式,以实现更高效和可靠的AI编码工具。
通过不断优化和训练,AI模型有望在不久的将来达到甚至超越人类博士水平,为各个领域带来革命性的变革。






