

ChatGPT的崛起与版权争议
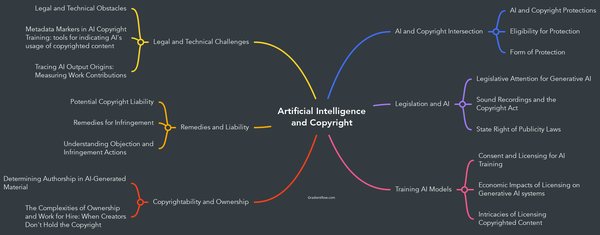
近年来,以ChatGPT为代表的生成式人工智能技术迅速崛起,改变了人们获取信息、创作内容的方式。然而,这一技术的快速发展也带来了诸多版权争议。人工智能并非“无中生有”,其依赖海量互联网信息进行训练,这不可避免地引发了关于知识产权与内容剽窃的讨论。
版权争议的典型案例
2024年,国内外均发生了多起颇具影响力的版权争议案例。例如,某知名人工智能公司因未经授权使用大量受版权保护的文学作品进行模型训练,被多家出版机构联合起诉。此类案件不仅引发了法律界的广泛关注,也促使社会各界重新审视人工智能与版权之间的关系。


语料训练中的版权挑战
中国人民大学国家版权贸易基地发布的“2024数字版权保护与发展年度关键词”中,“AI大模型语料训练版权挑战”位列第三。这一关键词揭示了当前人工智能发展中的一个核心问题:如何在保护创作者权益的同时,确保人工智能技术的持续创新。语料训练中的版权问题不仅涉及法律层面,更关系到整个数字内容产业的健康发展。
寻求平衡的路径
面对人工智能与版权之间的冲突,寻求平衡已成为当前必须面对的重大课题。以下是一些可能的解决路径:
-
加强法律法规建设:制定和完善相关法律法规,明确人工智能使用受版权保护材料的边界和条件。
-
建立授权机制:鼓励人工智能公司与版权方建立授权合作,通过合法途径获取训练数据。
-
推动技术革新:研发新技术,减少对受版权保护材料的依赖,如开发更高效的数据清洗和去重技术。
-
提升公众意识:加强版权教育,提高公众对人工智能与版权问题的认知,形成尊重知识产权的社会氛围。
结语
生成式人工智能技术的快速发展为人类社会带来了前所未有的机遇与挑战。在保护创作者权益与推动产业创新之间找到平衡,不仅需要法律和技术的支持,更需要社会各界的共同努力。只有如此,我们才能在人工智能时代实现可持续的创新发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章
暂无评论...









AI-magic收录了大量国内外AI工具箱,包括AI写作、图像、视频、音频、编程等各类AI工具,以及常用的AI学习、技术、和模型等信息,让你轻松加入人工智能浪潮。