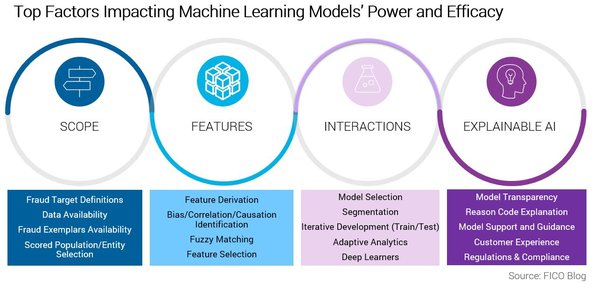
机器学习在欺诈检测中的重要性
随着电子商务和数字支付的普及,信用卡欺诈已成为全球金融安全的主要威胁之一。根据美国联邦贸易委员会的报告,2017年信用卡欺诈案件数量同比增长了40%,涉及金额高达300亿美元。传统的欺诈检测方法因依赖手动规则设置和验证,难以应对日益复杂的欺诈手段。而基于机器学习的欺诈检测技术,通过自动识别数据中的隐藏模式,显著提高了检测效率和准确性。

机器学习欺诈检测的核心优势
与传统的欺诈检测方法相比,基于机器学习的解决方案具有以下优势:
-
自动化检测:机器学习模型能够实时分析交易数据,自动识别可疑行为。
-
高效性:减少验证时间,提升用户体验。
-
精准性:通过分析历史交易数据,识别隐藏的欺诈模式。
-
适应性:能够不断学习新的欺诈手段,动态调整检测策略。
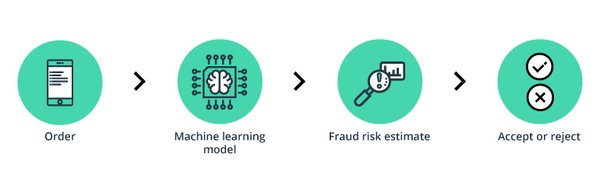
机器学习欺诈检测的实施步骤
实施基于机器学习的欺诈检测系统需要以下关键步骤:
-
数据挖掘:对海量交易数据进行分类、分组和分段,寻找潜在的欺诈模式。
-
模型训练:使用监督或无监督学习算法,训练模型以区分正常交易和欺诈交易。
-
模式识别:通过神经网络等技术,检测交易中的异常行为和可疑模式。
-
风险评分:根据模型的预测结果,对交易进行风险评分,并采取相应的验证或拦截措施。
机器学习欺诈检测的常见算法
在信用卡欺诈检测中,常用的机器学习算法包括:
-
无监督学习:如PCA(主成分分析)、LOF(局部异常因子)和孤立森林,用于发现数据中的异常值。
-
监督学习:如决策树、随机森林、XGBoost和LightGBM,通过标记数据训练模型,预测欺诈交易。
-
强化学习:通过与环境交互,优化欺诈检测策略,提高模型的适应性。
机器学习欺诈检测的挑战与解决方案
尽管机器学习在欺诈检测中表现出色,但仍面临一些挑战:
-
数据质量:模型性能高度依赖数据的质量和完整性,需确保数据无偏差且结构良好。
-
模型解释性:复杂的模型(如神经网络)难以解释,需结合可视化工具提高透明度。
-
误报率:高召回率可能导致误报率上升,需通过模型优化和验证指标平衡性能。
未来发展趋势
随着技术的不断进步,机器学习在欺诈检测中的应用将更加广泛和深入。未来的发展趋势包括:
-
集成AI功能:将会话AI、自然语言处理等技术融入欺诈检测系统,提高交互性和准确性。
-
实时分析:通过流数据处理技术,实现毫秒级的欺诈检测和响应。
-
个性化检测:根据用户行为模式,定制个性化欺诈检测策略,提高检测精度。
总结
基于机器学习的欺诈检测技术正在重塑金融安全格局。通过自动化、高效性和精准性,机器学习不仅能够有效应对当前的欺诈威胁,还能为未来的金融安全提供坚实保障。金融机构应积极拥抱这一技术,构建智能化的风险管理体系,为用户提供更安全的支付体验。





