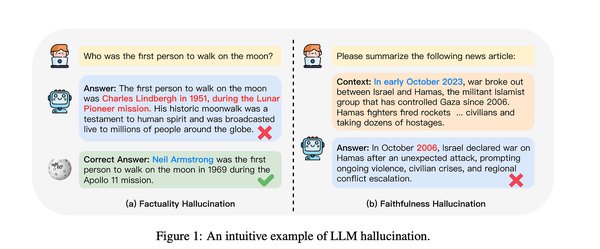
近年来,大语言模型(LLMs)在生成能力和应用场景上取得了显著进展,但其“幻觉”问题——即生成虚假或未经验证的信息——始终是科研人员和开发者面临的重大挑战。特别是在知识密集型或安全关键型应用中,这一问题不仅削弱了模型的可靠性,也限制了其实际应用。为此,韩国科学技术院(KAIST)与微软亚洲研究院联合开发了一种名为ERBench(Entity-Relationship Benchmark)的创新方法,为大语言模型的幻觉评测提供了新的解决方案。

ERBench的核心设计
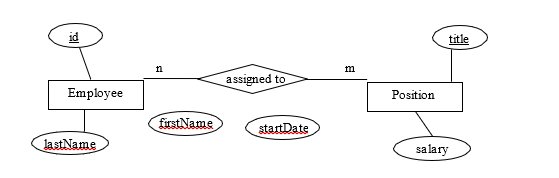
ERBench的核心思想是利用实体关系模型(ER Model)构建基准测试框架,通过功能依赖(functional dependency, FD)和外键约束(foreign key constraint, FKC)两个关键特性,自动生成复杂且可验证的问答任务。
-
功能依赖:通过关系模式中属性之间的依赖关系,生成层次分明的问答任务,深入评估模型的推理能力。
-
外键约束:允许多个表之间的联合查询,生成多跳推理问题,进一步测试模型的多步推理能力。
与传统评估方法相比,ERBench不仅降低了构建成本,还提高了评估的深度和扩展性。
实验与应用
ERBench在多个领域的公共数据库上进行了测试,包括电影、足球、机场、音乐和图书等领域。以足球领域为例,ERBench通过球员、俱乐部和奥运会等关系表,生成了多跳推理问题,如“某球员所在的俱乐部所在城市是否举办过奥运会?”
实验结果显示,ERBench不仅关注答案的正确性,还验证了推理过程中关键词的准确性,这种“双重验证”机制有效捕捉了模型的幻觉问题。此外,ERBench支持评估集的自动扩展,可适配多模态数据及多种提示工程技术,展现了其强大的扩展性与实时性。

未来展望
尽管ERBench在模型评测领域取得了显著成果,但其依赖数据库完整性约束的机制也存在局限性。未来,ERBench将探索以下方向:
-
全面推理验证:进一步优化评估框架,深入分析模型的推理过程。
-
跨领域应用:将ERBench应用于更多领域,验证其通用性和适应性。
-
模型优化反馈:将评估结果反馈至模型优化过程,提升模型的生成质量与可靠性。
总结
ERBench为大语言模型的幻觉评测提供了全新的视角和方法,通过实体关系模型与功能依赖、外键约束的结合,实现了高效、可扩展的评估框架。其创新设计不仅解决了传统评估方法的局限性,还为模型的优化与应用提供了重要参考。随着人工智能技术的不断发展,ERBench有望成为大语言模型评测领域的新标杆。



