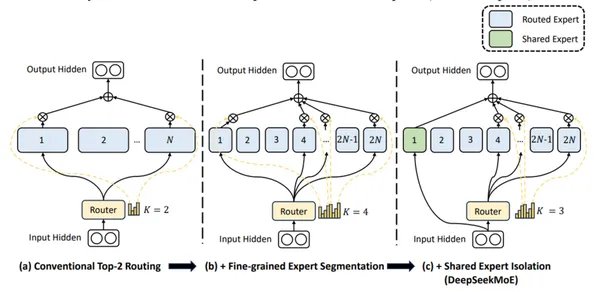
混合专家模型(MoE)的崛起
混合专家模型(Mixture-of-Experts,MoE)近年来在人工智能领域崭露头角,成为提升模型性能的重要架构。MoE通过将多个专家网络组合在一起,每个专家负责处理特定类型的任务,从而在保持高效计算的同时,显著提升模型的泛化能力和鲁棒性。DeepSeek的MoE架构正是这一技术的杰出代表,其在自然语言处理和计算机视觉等领域的广泛应用,证明了MoE的强大潜力。

DeepEP:MoE的“AI快递高速路系统”
2025年2月25日,DeepSeek在“开源周”中推出了DeepEP通信库,这是专为MoE模型训练和推理设计的专家并行(Expert Parallelism,EP)通信库。DeepEP通过优化NVLink和RDMA技术,实现了极速传输、智能分拣与压缩,显著降低了训练成本并提升了推理速度。某自动驾驶公司借助DeepEP,节省了2亿元的训练成本,推理速度提升了3倍。
DeepEP的创新点
-
高吞吐量的all-to-all GPU算子:这些算子主要用于实现MoE模型中的分发(dispatch)和合并(combine)操作,是MoE架构的核心通信环节。
-
低精度计算支持:支持包括FP8在内的低精度计算,减少计算资源消耗并提高训练和推理速度。
-
分组限制门控算法优化:优化后的算子专门处理跨异构网络域的带宽转发,如从NVLink域到RDMA域的数据转发。
-
推理场景优化:针对延迟敏感的推理解码场景,实现了基于纯RDMA的低延迟算子,最小化通信延迟。
-
创新的通信计算重叠方法:引入基于钩子(hook-based)的通信计算重叠方法,无需占用流式多处理器(SM)资源,进一步提高计算效率。

DeepEP的实际应用与影响
DeepEP的出现为MoE模型的训练和部署提供了重要支持。优化后的通信系统可使千亿参数模型的训练成本大幅降低。高吞吐量特性使其特别适用于模型训练和推理预填充(prefilling)阶段,显著提升效率。DeepEP支持节点内和节点间的通信,提供了更灵活的部署选择。该库支持对流式多处理器(SM)数量的精确控制,使资源分配更加高效。
未来展望
DeepEP的开源不仅打破了英伟达NVLink性能天花板,还推动了医疗、金融等领域的MoE模型落地。开源24小时内,DeepEP在GitHub上飙涨1500星,被誉为“AI从堆硬件转向智能优化的里程碑”。未来,随着技术的不断进步,我们有理由期待DeepEP在更多复杂任务和场景中的应用,为我们的生活带来更多的便利和惊喜。
通过DeepEP,DeepSeek再次证明了其在AI领域的创新能力,为混合专家模型的发展开辟了新的道路。




